

Geospatial data has always been more than dots on a map – it’s actually a way for describing how people, cultures, and economies actually reach across distance. Borders drawn on maps rarely match the lived reality of a place: families split by a new frontier still call each other, diaspora communities still send money home, and workers still follow the same seasonal routes their parents did. Mapping these ties turns history and migration into something visible, revealing the world as a network of relationships that geography alone can’t fully explain.
Meta and a team of NYU Stern economists have just released an updated version of the Social Connectedness Index (SCI). The SCI measures the relative probability that two people in different places are Facebook friends. That sounds like a strange thing to build a research dataset around, but it turns out to be a good proxy for the real social ties that connect places: migration corridors, minority communities split by a border redrawn a century ago, seasonal labour circuits, whatever has moved people between two spots over time.
The 2026 release covers 178 countries, with subnational data down to GADM level 2, geoBoundaries units, NUTS regions, and US counties and ZIP codes.
What the index actually measures
For any pair of locations, the SCI is built from anonymised Facebook friendship data, scaled so that the strongest observed connection in a file gets a value near 1,000,000 and the weakest gets a value near 1. If the SCI between Warsaw and London is twice that between Warsaw and Madrid, a randomly chosen Facebook user in Warsaw is roughly twice as likely to be friends with someone in London as with someone in Madrid.
It isn’t a measure of friendship intensity or contact frequency, and it says nothing about people who aren’t on Facebook. But at the scale of countries and regions, it picks up something real: places with a shared border, a migration wave, or a minority population tend to show up strongly connected, while political boundaries and plain distance suppress the number even between close neighbours.
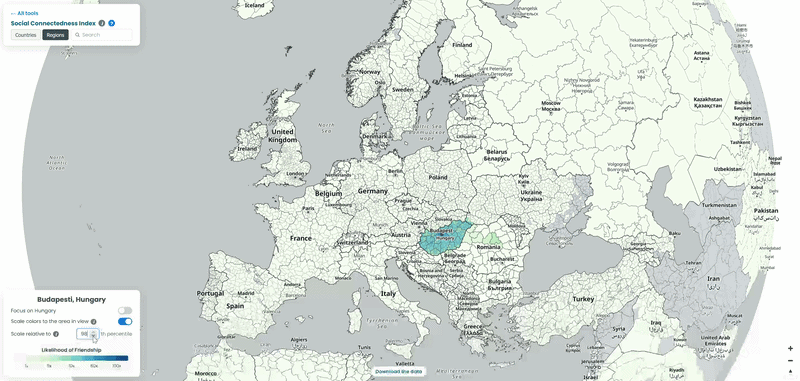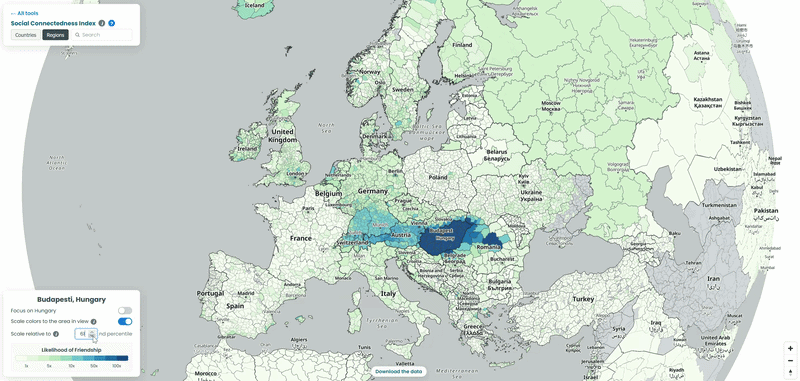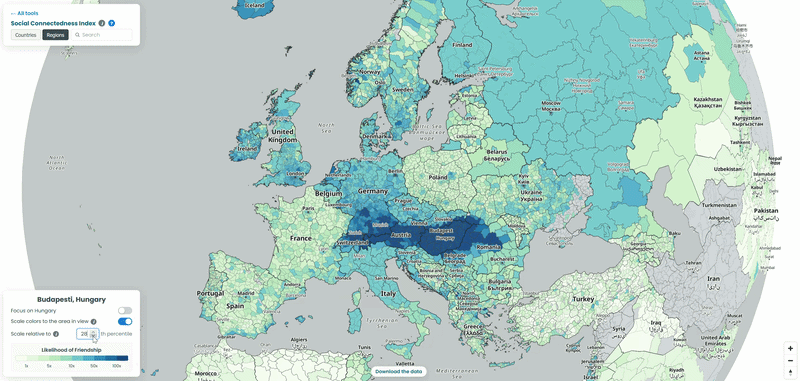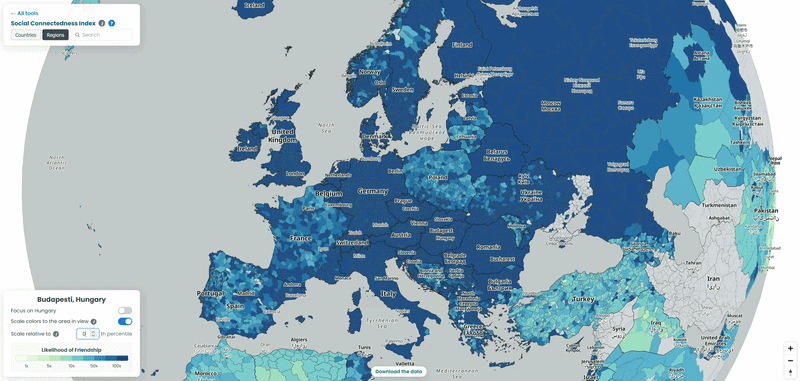
For each country in our example, we pulled the top 10 connections for every NUTS3-level region to a location outside its own borders, then looked at which neighboring countries absorbed the largest share of those cross-border ties. To explore the data yourself, choose a country from the list and interact with the map – zoom in to see regional detail or zoom out to trace how its connections extend across borders. We also played with the “Scale relative to Xth percentile” slider on the SCI explorer, moving it from 100 down to 1, to see how the visible connections from the capitals of each country shift as weaker ties are revealed (See examples below!).
Hungary’s counties are tied to their historical minorities
The Romanian and Serbian numbers aren’t spread evenly across those countries. They concentrate hard in a handful of specific counties: Harghita and Covasna in Romania, and North Bačka and North Banat in Serbia. Those four happen to be the parts of Transylvania and Vojvodina with the largest ethnic Hungarian populations left over from the 1920 border changes after the First World War. A century later, that history still shows up clearly in who’s friends with whom on Facebook. The Austrian connections tell a more simple, present-day story: they cluster in Tyrol and around Salzburg, both regions that pull in Hungarian seasonal workers for tourism and hospitality.
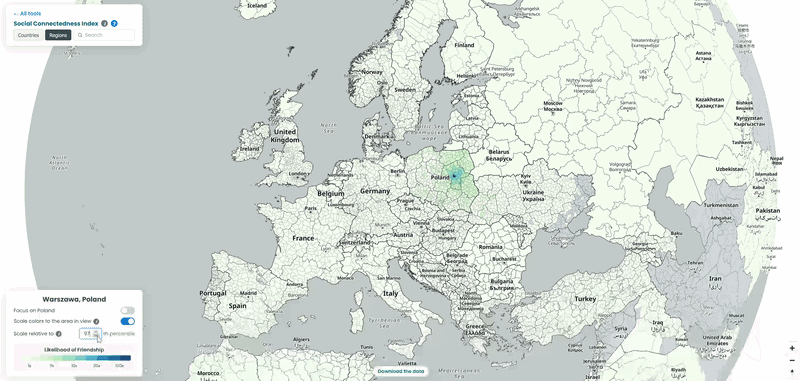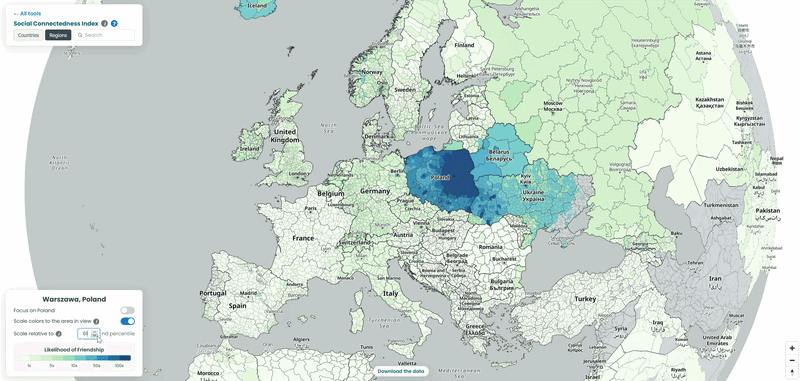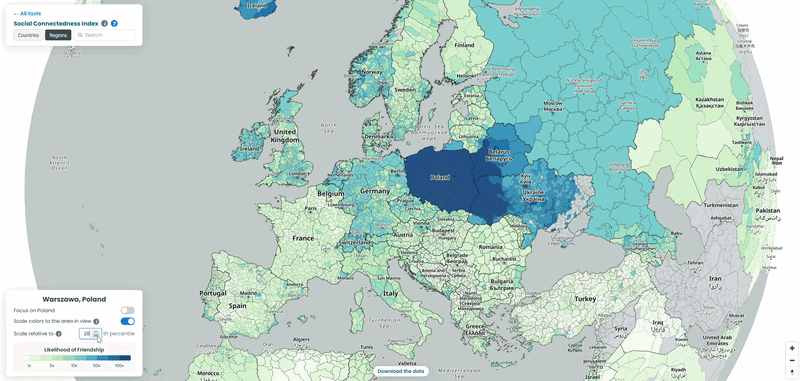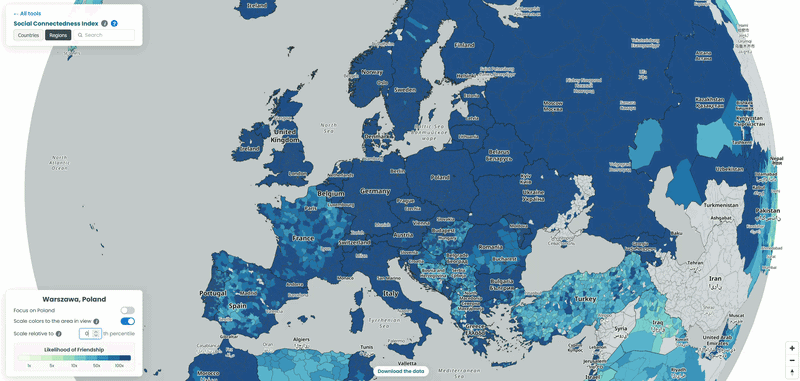
Poland’s counties point at the neighbours and western-european countries
In the interactive map, the top connections from Polish counties are dominated by Western European countries: Germany leads by a wide margin, with the Netherlands, Switzerland, Norway and, more surprisingly, Iceland also standing out. Worth noting: Ukraine and Belarus don’t appear here at all, because both are missing from the underlying SCI dataset – they are, however, included in the map on the SCI explorer itself (See visual below!).
The Iceland connection is easy to miss but worth pausing on. It splits fairly evenly between the capital region around Reykjavik and the rest of the country, which lines up with something well-documented but rarely visualised: Poles are the largest immigrant group in Iceland, and they’re spread across fishing and tourism towns nationwide, not clustered in the capital the way most migrant communities are. The interactive map reads as a fairly clean picture of the labour migration that followed Poland’s 2004 EU accession.
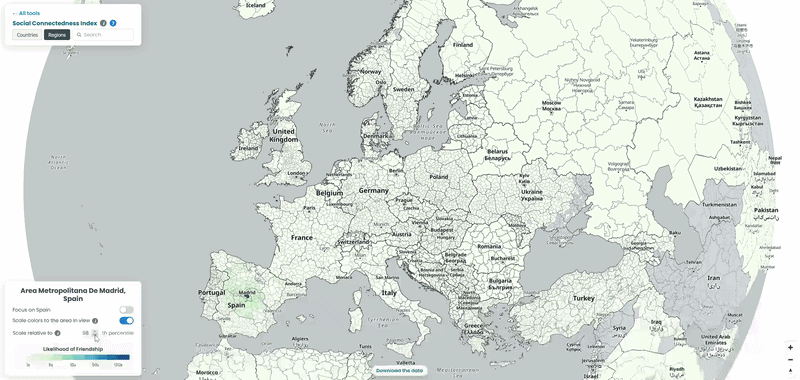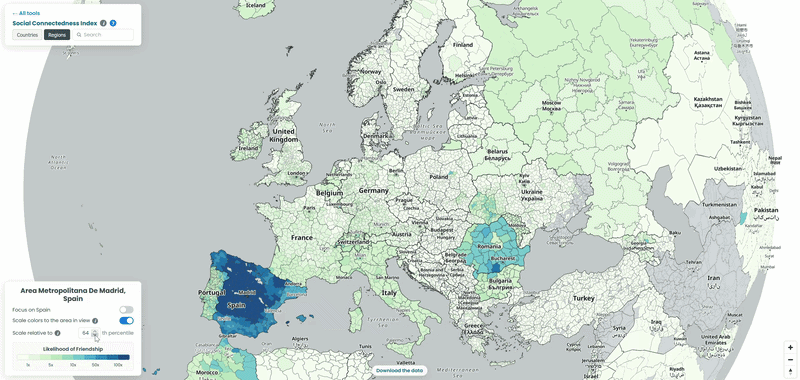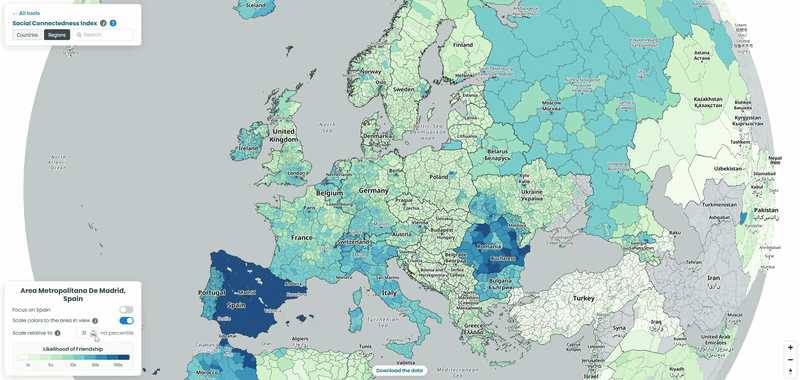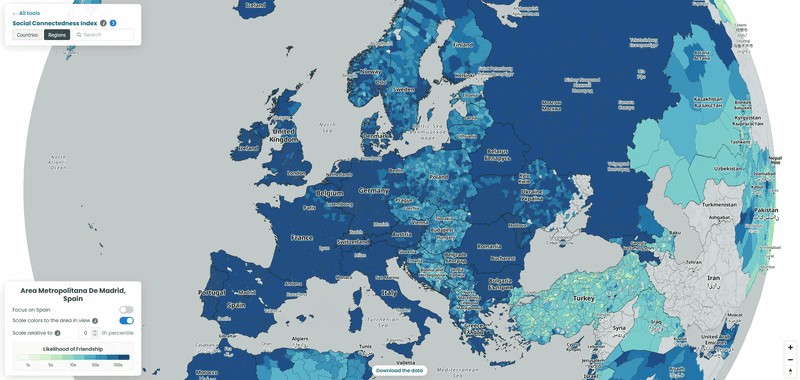
Spain’s strongest ties abroad go to Romania!
Romania takes by far the largest share of top connections from Spanish counties, well ahead of Portugal, despite Portugal sharing a land border with Spain and Romania being over 2,000 kilometres away. It matches a real, large migration story: Spain has one of the largest Romanian communities in Europe, built up over roughly two decades of labour migration, concentrated in agriculture and construction. Bulgaria shows up too following a similar pattern. It’s a good example of the SCI’s core finding holding up here in reverse: distance normally predicts connectedness well, and this is a case where migration history overrides it completely.
Germany’s connections read like a map of its guest worker and refugee history
Germany has 400 NUTS3 districts (the most of any country in the release) so this map has the most going on. Balcan countries lead the top connections, followed by a cluster in Austrian nd Switzerland. Kosovo and North Macedonia are the two that stand out, since neither is an EU member and neither shares a border with Germany. Both trace back to the same source: the large Kosovar and North Macedonian diaspora built up first through the 1960s-80s Gastarbeiter recruitment programmes and then reinforced by refugee movements during and after the Yugoslav wars. Greece’s presence is the older half of the same Gastarbeiter story. It’s a rare case of a single dataset making six decades of labour and refugee migration visible in one picture.
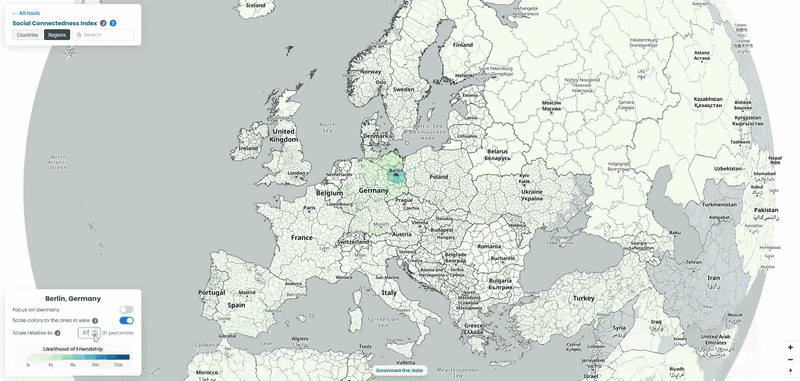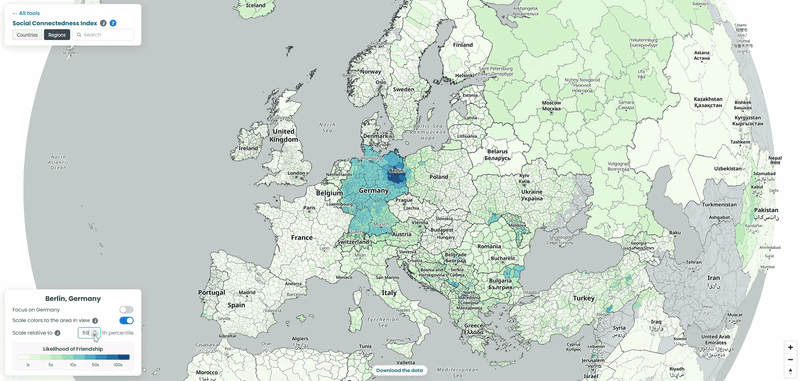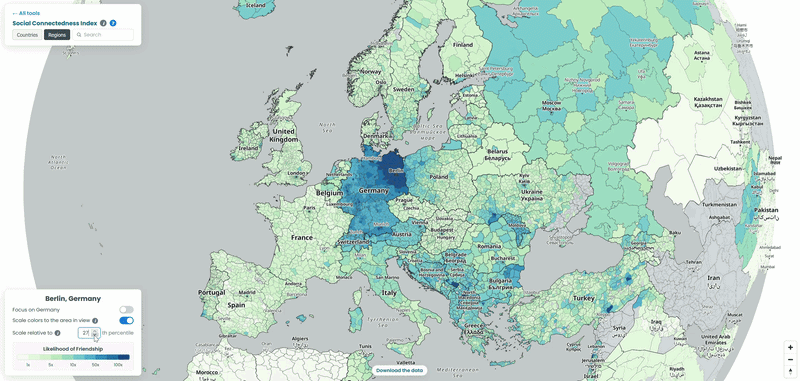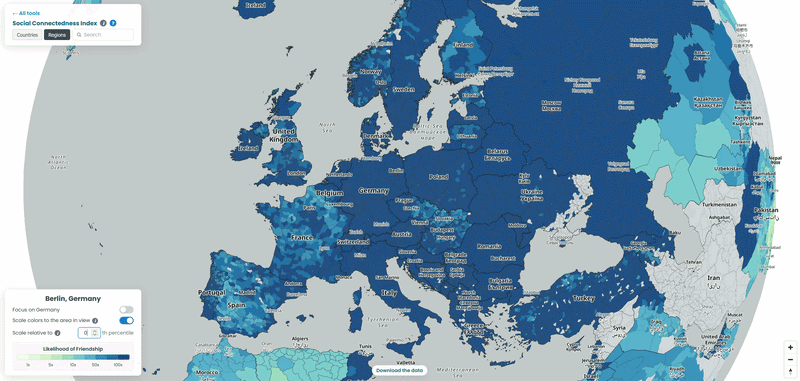
How far does the NUTS data actually reach?
All four interactive maps above use the SCI’s NUTS 2024 file, which only covers Europe. Worth knowing exactly how far “Europe” goes here before reading too much into any gaps: the file has region-level data for 36 countries, from Germany’s 454 districts down to 3 each for Cyprus, Luxembourg, and Montenegro. Turkey is included as a candidate country, as are Albania, Serbia, North Macedonia, Bosnia and Herzegovina, and Montenegro. Iceland, Norway, and Switzerland are in as EFTA members. Anywhere outside that list, this particular file has nothing to say, even if the country-to-country SCI file covers it.
Where to get the data
The full SCI dataset, including the country-to-country, GADM, geoBoundaries, NUTS, and US county and ZIP code files, is freely available through the Humanitarian Data Exchange. Meta’s team also runs an interactive explorer for browsing connectedness maps without writing any code, and a companion GitHub repository with an R-based mapping tool for more advanced use.
Data like this only becomes useful once it’s put on a map, and GIS tools make that operation straightforward. But turning a spreadsheet of index values into a convincing map comes with a responsibility to be clear about what’s actually being shown. The SCI is a proxy built from one platform’s friendship data, not a census of who is connected to whom, and its coverage gaps can just as easily be mistaken for an absence of real-world ties as for a gap in the source. Anyone building on this data, or reading a map made from it, should treat it the way you’d treat any single proxy: a signal worth exploring, not a complete picture on its own.
References
Johnston, D., Kuchler, T., Kulkarni, M., & Stroebel, J. (2026). The Social Connectedness Index. Data in Brief.
Bailey, M., Cao, R., Kuchler, T., Stroebel, J., & Wong, A. (2018). Social Connectedness: Measurement, Determinants, and Effects. Journal of Economic Perspectives, 32(3), 259-280.
How do you like this article? Read more and subscribe to our monthly newsletter!

#Fun
Next article

Rethinking Benchmarks in GeoAI: Why Bigger Earth Observation Models Are Not Automatically Better

For years, many Earth observation systems were trained to perform specific tasks: detect buildings, map roads, classify land cover, or segment floodwater. Now the field is moving toward larger geospatial foundation models trained on satellite imagery, aerial imagery, maps, and weather and environmental data. Models such as Prithvi-EO-2.0 and Clay v1.5 show how this space is growing, with applications ranging from land-use and crop mapping to disaster response, flood mapping, and ecosystem monitoring. These models are designed to support many downstream tasks instead of being trained from scratch for each one. The same base model can be adapted to new regions, sensors, and mapping problems with less labelled data than a task-specific model.
The question is no longer only: can we build larger geospatial models? It is also: can we honestly measure where these models work, where they fail, and whether they can be trusted outside benchmark datasets?
This is where GeoAI starts to face a benchmark crisis. A model can score well on a public dataset and still fail in a different geography, season, sensor type, or disaster context. Recent work argues that evaluation should consider generalization, transferability, energy use, and real-world impact, not only accuracy.
This article looks at why standard AI benchmarks do not translate cleanly to geography, why one-number scores can hide important failures, and what a better GeoAI evaluation should look like.
Why Conventional AI Benchmarks Do Not Translate Cleanly to Geography
Most computer vision benchmarks are built around objects that stay visually recognizable across many photos. A car, dog, or coffee cup may change in colour, angle, or lighting, but the object category often remains fairly stable.
Earth observation does not behave like that. In satellite and aerial imagery, the same class can look very different depending on region, resolution, season, sensor, atmosphere, and local settlement patterns. A building in Germany, India, Kenya, and Brazil may differ in roof material, spacing, shape, density, and surrounding road structure. This is why cross-region building detection is hard.
Flood mapping has the same problem. In optical imagery, floodwater may be hidden by clouds during the exact storms when mapping is most urgent. In SAR imagery, water is often visible through clouds, but it appears differently and can be confused with other smooth surfaces. A crop field also changes with climate, irrigation, soil type, planting calendar, and growth stage. The same crop can look different across regions and seasons.
This is why GeoAI benchmarks cannot be treated as neutral scoreboards. The score is shaped by where the data was collected, which sensor was used, how labels were produced, and when the imagery was captured. Newer benchmarks are starting to test spatial reasoning more directly, including distance, direction, topology, and geometry-based questions. Earlier efforts also show the need for Earth-observation-specific evaluation rather than borrowing benchmark habits from ordinary computer vision.
The Problem With One-Number Performance Scores
GeoAI models are often compared using a single metric: accuracy, F1-score, IoU, mAP, or AUROC. These scores are useful, but they can also hide the failures that matter most in the real world.
The easiest example is class imbalance. In flood mapping, water may cover only a small part of the image. If a model predicts “no flood” almost everywhere, it can still produce a high overall accuracy because most pixels are background. The number looks promising, but the model has failed the actual task.
This problem appears across many geospatial applications. A building detector trained mainly on planned urban areas may perform well in cities with regular street grids, but miss buildings in dense informal settlements. A land-cover model trained mostly on temperate regions may degrade when applied to tropical forests, arid landscapes, or mixed agro-urban areas. A disaster-mapping model trained on clear-sky or moderate-event imagery may score well in benchmark tests, but fail during cloudy monsoon flooding, mountainous landslides, or extreme wildfire events.
In GeoAI, an average score can hide exactly the places where the model matters most.
Metrics also measure different aspects. IoU measures overlap between prediction and ground truth, but boundary errors can be treated poorly in some cases. Research on Boundary IoU shows that standard mask IoU can miss important boundary-quality differences. For object detection, mAP summarizes precision and recall across thresholds, but it does not explain whether errors happen in wealthy city centers, rural roads, or disaster-hit settlements. A general object detection metrics guide can explain the formulas, but geospatial deployment needs more context than the formula itself.
Remote sensing also faces out-of-distribution problems. A 2024 study on OOD detection in remote sensing underscores that identifying unfamiliar scene types stops models from blindly forcing new, unseen land categories into existing labels with dangerously high confidence.
For GeoAI, the problem is not that metrics are useless. The problem is treating one score as the whole story.
Geography Creates Evaluation Problems That Most Benchmarks Miss
To build GeoAI models that people can trust, evaluation has to reflect how the Earth actually varies. A random train-test split is often not enough. The test set may look statistically separate, but still come from the same geography, sensor, season, and event type as the training data.
The first issue is region. A model trained mostly on North America or Western Europe may not work the same way in South Asia, Africa, or Latin America. Buildings, roads, farms, and vegetation follow different local patterns. This is why testing models across diverse, unseen geographies is critical to overcoming spatial domain shift.
The second issue is sensor. Sentinel-2, Landsat, PlanetScope, Maxar, aerial imagery, drone imagery, and SAR do not capture the world in the same way. They differ in resolution, spectral bands, revisit time, viewing geometry, and noise. For example, a study on cross-sensor adaptation uses high-resolution Gaofen-2 imagery and Sentinel-2-derived data to show that even when the land-use classes are the same, differences in spatial detail and sensor characteristics can reduce model transferability.
The third issue is scale. A model trained at 10 m resolution may not behave the same way on 30 cm aerial imagery. At coarse resolution, a building may be only a few pixels. At high resolution, the model sees roof material, shadows, cars, trees, and yard boundaries. The object is the same, but the visual problem changes.
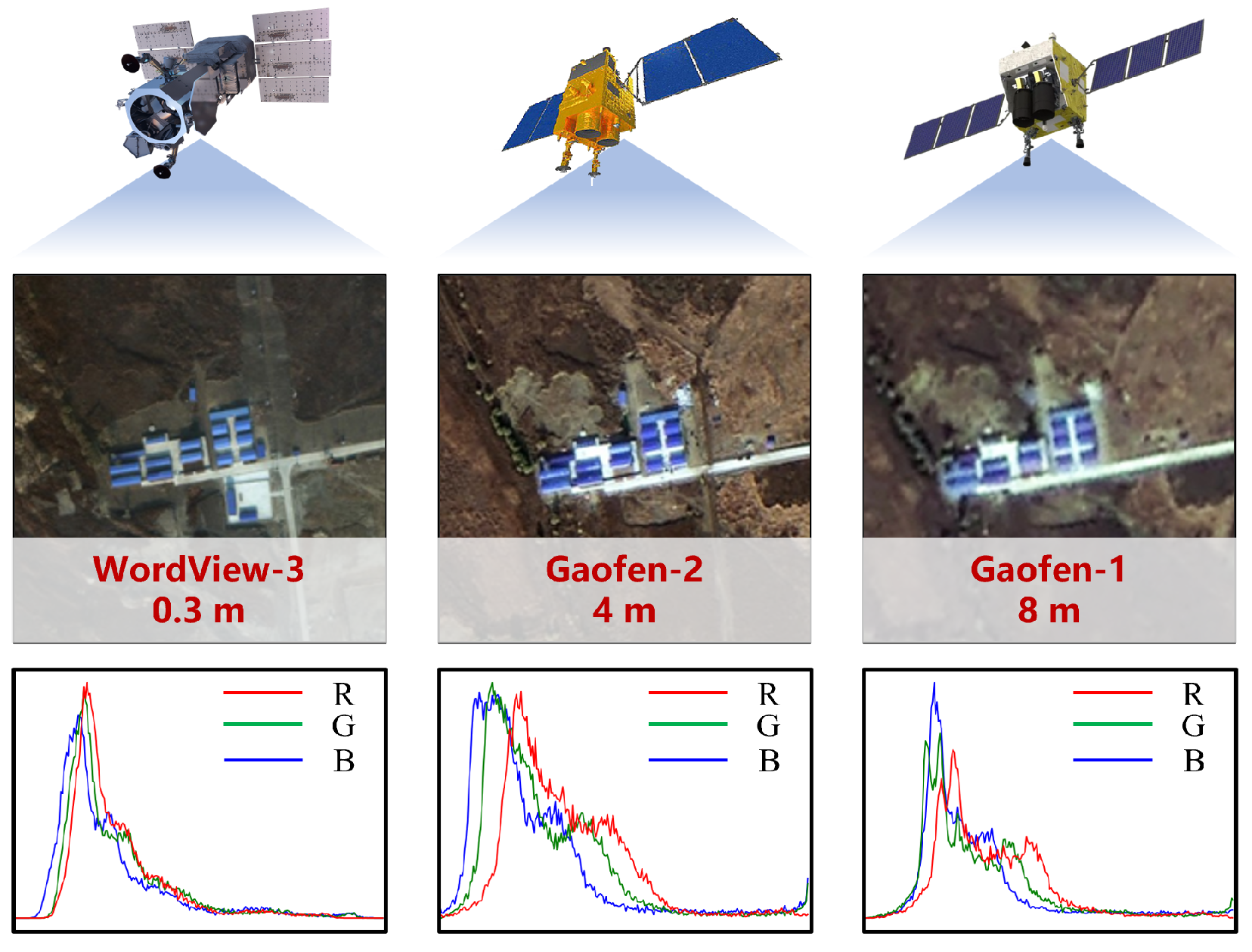
High-resolution visible imagery from different sources varies in terms of spatial resolution and spectral characteristics. Source: Li et al., 2025
The fourth issue is time. Vegetation, snow, water bodies, crop cycles, soil moisture, and shadows change across seasons. A model tested only on summer imagery may give a false sense of reliability.
The fifth issue is rare events. Floods, landslides, wildfires, oil spills, volcanic activity, and infrastructure failures are often underrepresented, but these are the cases where GeoAI is most needed. Newer work such as GeoDisaster and real-world distribution-shift benchmarks for satellite object detection show why evaluation must include hazards, geography, and operational context.
What Better GeoAI Benchmarks Should Look Like
Better GeoAI benchmarks should not only ask which model gets the highest score. They should ask where the model works, where it fails, and what kind of evidence is needed before it can be trusted.
That means moving away from static leaderboards built around one average number. A useful benchmark should report regional breakdowns instead of only global averages. It should show whether a model performs differently across continents, climate zones, urban forms, and income contexts. It should also separate results by sensor and resolution, because performance on Sentinel-2 does not automatically mean performance on aerial imagery, SAR, or commercial high-resolution data.
Time matters too. Benchmarks should include seasonal and temporal splits, not only random train-test splits. A model tested on data from a different year, season, or event is more likely to reveal whether it has learned a robust pattern or only memorized familiar conditions.
Uncertainty should also become standard. If a model sees a landscape, sensor type, or disaster pattern it does not understand, it should say so. Work on predictive uncertainty in remote sensing shows why this matters: a model trained on one environment, such as forest or European urban imagery, can fail on very different urban scenes while still giving a confident prediction.
Newer benchmarks are starting to move in this direction. GEOBench-VLM evaluates vision-language models on scene understanding, counting, localization, fine-grained categories, and temporal analysis. GS-QA tests geospatial question answering using OpenStreetMap and Wikipedia data, including distance and angular error. GeoAnalystBench evaluates whether language models can generate valid spatial-analysis workflows and code. TurnBack tests route cognition across 36,000 routes in 12 cities.
The best benchmark is not the one that makes models look good. It is the one that reveals where they break.GeoAI does not need only larger models. It also needs better ways to test them.
Did you like this post?
Read more and subscribe to our monthly newsletter!

