
A Global Road Surface Type Classification Dataset Powered By Deep Learning and Mapillary Data

The Importance of Surface Data Drives Transportation, Safety, and Economic Development
Road surface information plays a crucial role in various sectors, from transportation safety to economic growth and environmental sustainability. Accurate road surface data informs decisions around route planning, driving conditions, and emergency response logistics.
For instance, unpaved roads, especially in wet or poorly maintained conditions, pose increased risks of accidents, while knowledge of road types (paved vs. unpaved) aids in selecting appropriate routes for ambulances, fire trucks, or other emergency services in areas with limited infrastructure.
This data also optimizes supply chains, agricultural infrastructure, and logistics, reducing transportation costs and delays. For tech applications like Open Street Map (OSM), and GPS systems, reliable road surface data improves routing, especially in rural and underdeveloped regions, enhancing navigation and route selection for drivers.
Beyond Building Footprints: Enriching OSM Attributes
Enriching OpenStreetMap (OSM) with detailed attributes is essential for maximizing its value as a tool for decision-making and efficient service delivery. While OSM provides an impressive level of global road coverage—estimated at about 83%—significant gaps remain in critical metadata, such as road surface types. Only 30-40% of roads in the dataset have surface type information, and this deficiency is even more pronounced in developing regions.
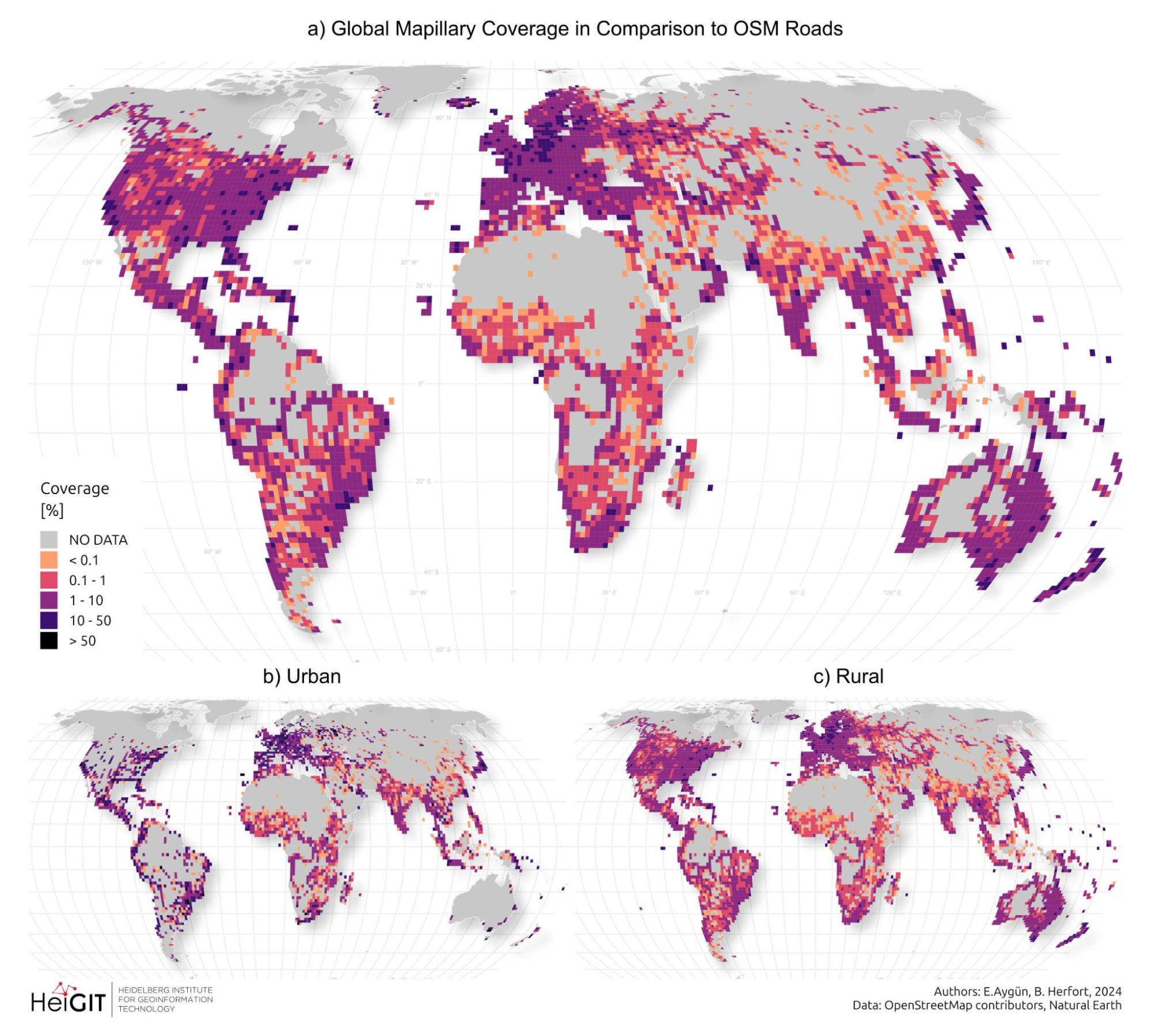
Global overview of spatial distribution of OpenStreetMap (OSM) road length coverage derived from Mapillary data (based on zoom 8 tiles). The maps illustrate: (a) Total OSM Road Length Coverage, (b) Urban OSM Road Length Coverage, and (c) Rural OSM road Length Coverage, showing the varying degrees of coverage across different regions of the world. The color gradient from blue to yellow indicates the percentage of length coverage, with lighter colors representing higher coverage.
To address this, we at HeiGIT (Heidelberg Institute for Geoinformation Technology), are releasing a global dataset on road surface types (paved or unpaved), contributing to humanitarian response, urban planning, and economic development goals. By making this information openly available, we aim to enrich global mapping efforts, especially in regions lacking detailed infrastructure data.
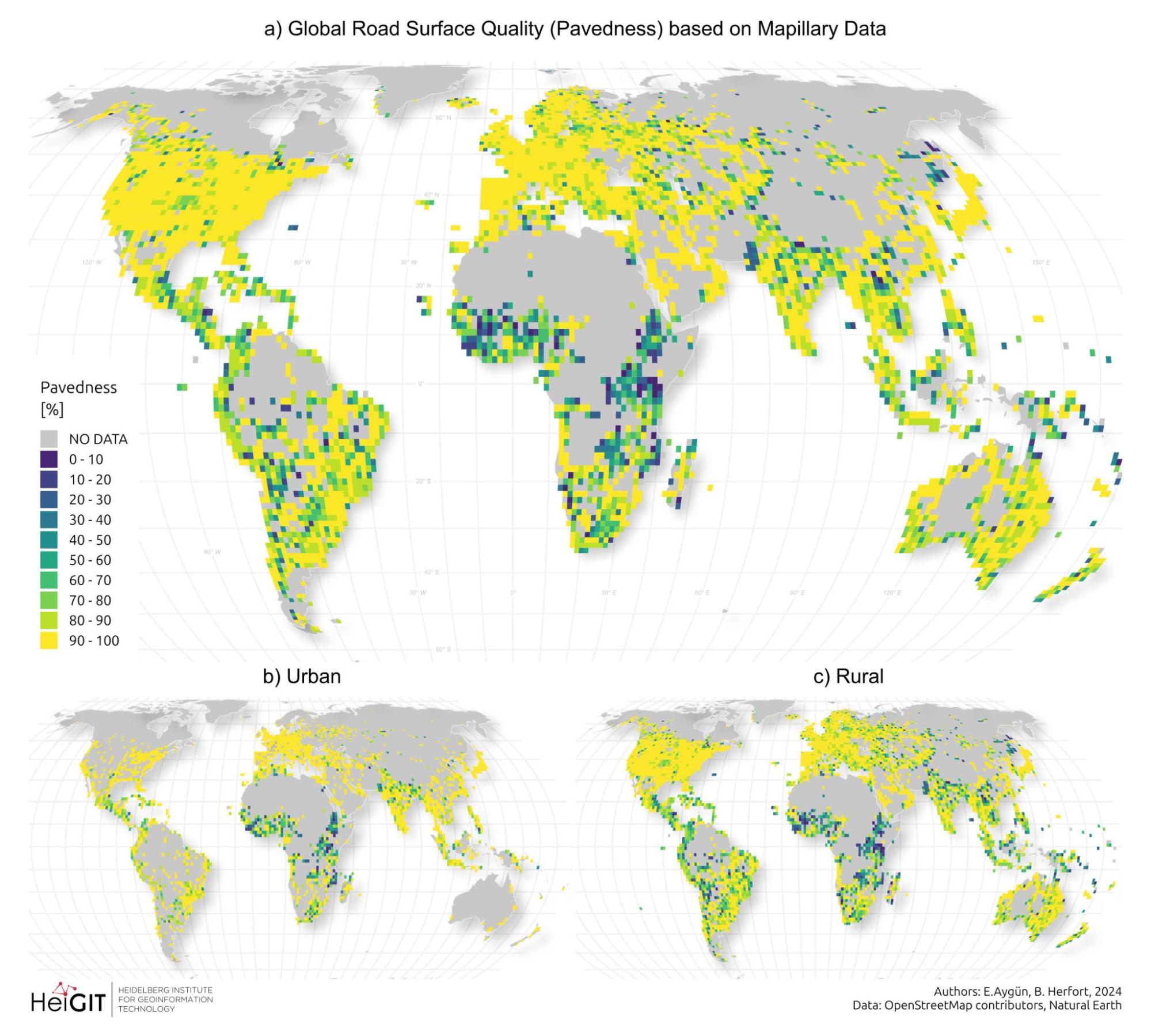
Distribution of road surface quality predicted based on Mapillary data: (a) total pavedness (defined as the ratio of total paved roads w.r.t total OSM roads for each zoom 8 tile), (b) and (c) pavedness per tile, calculated for urban and rural areas respectively.
How We’re Using Deep Learning to Classify Road Surfaces
At HeiGIT, we’ve made significant strides in improving global road surface classification using cutting-edge deep learning techniques. A major challenge is the diversity of road imagery, especially from crowdsourced platforms like Mapillary, which provides vast street-view images worldwide. To address this, we deployed a SWIN-Transformer model pre-trained on the ImageNet-1k dataset and fine-tuned it on our own street-view imagery, creating a planet-scale application that sets new benchmarks for road surface classification accuracy.
Why the SWIN-Transformer?
We chose the SWIN-Transformer (Shifted Window Transformer) architecture because of its proven ability to establish long-range dependencies, making it highly effective at extracting global features from images. This model excels with heterogeneous data, like street-view imagery from various regions, as it captures fine-grained details crucial for road surface classification. Its ability to analyze the surrounding context enhances classification accuracy.
Crowdsourced Data and Training
The training dataset for our model came from an event at Heidelberg University in July 2023, where 30 volunteers participated in a mapathon using the HeiGIT CrowdMap web application. These volunteers labeled 20,000 random Mapillary images from 39 countries in sub-Saharan Africa, classifying them as “paved,” “unpaved,” or “bad imagery.” This labeling process played a critical role in building a reliable training set for the model.
Once the data was collected, we split the dataset into training and validation sets. After training, our model achieved a validation accuracy of 98.5%. To optimize the model’s performance, images in the training set were cropped from their original size of 2000×1200 pixels to 427×256 pixels, improving time and space complexity without sacrificing classification accuracy. To enhance the model’s robustness, we used data augmentation techniques, increasing the diversity of the images and improving the model’s generalization capabilities.
Tackling Anomalous Images with Advanced Filtering
One of the challenges we encountered during this process was the presence of anomalous images that didn’t contain any roads, such as images featuring sidewalks, side views, or tracks. These images, though unrelated to the task at hand, were being classified with respect to road surface information, which introduced noise into the dataset.
To address this, we implemented a combination filter using two additional models:
- A Fast Semantic Segmentation Model: Based on the PIDNet architecture, pre-trained on the Cityscapes dataset, this model was used to filter out images where road pixels comprised less than 10% of the total pixels. This ensured that only images containing substantial road views were considered for classification.
- CLIP Model for Zero-Shot Classification: We also incorporated CLIP (Contrastive Language–Image Pre-training), a zero-shot classification model based on the ViT-L/14 Transformer architecture. This model helped identify images with no roads by using two predefined classes: “a photo of a road” and “a photo with no road in it.” If the model predicted an image to be “a photo with no road in it” with a probability score of greater than 90%, it was filtered out.
The final filtering process removed images where the road pixel coverage was less than 10%, or where the CLIP model confidently predicted the absence of roads. This filtering stage eliminated approximately 4-5% of the total images, ensuring that our model only analyzed relevant data.
Performance and Validation: How Well Does It Work?
Once trained, the SWIN-Transformer model was validated against OpenStreetMap (OSM) surface data using a total of 5.16 million images from around the world.
The results were impressive, with F1 scores ranging from 91% to 97% for paved roads across different continents. However, there was some overestimation for the prediction of unpaved roads which was largely impacted due to the heterogeneous quality of Mapillary
Images lacked clear, direct frontal views of roads and instead consisted of side views of houses, driveways, and landscapes. This validation confirmed the model’s robustness and reliability in classifying the majority of road surfaces accurately on a global scale.
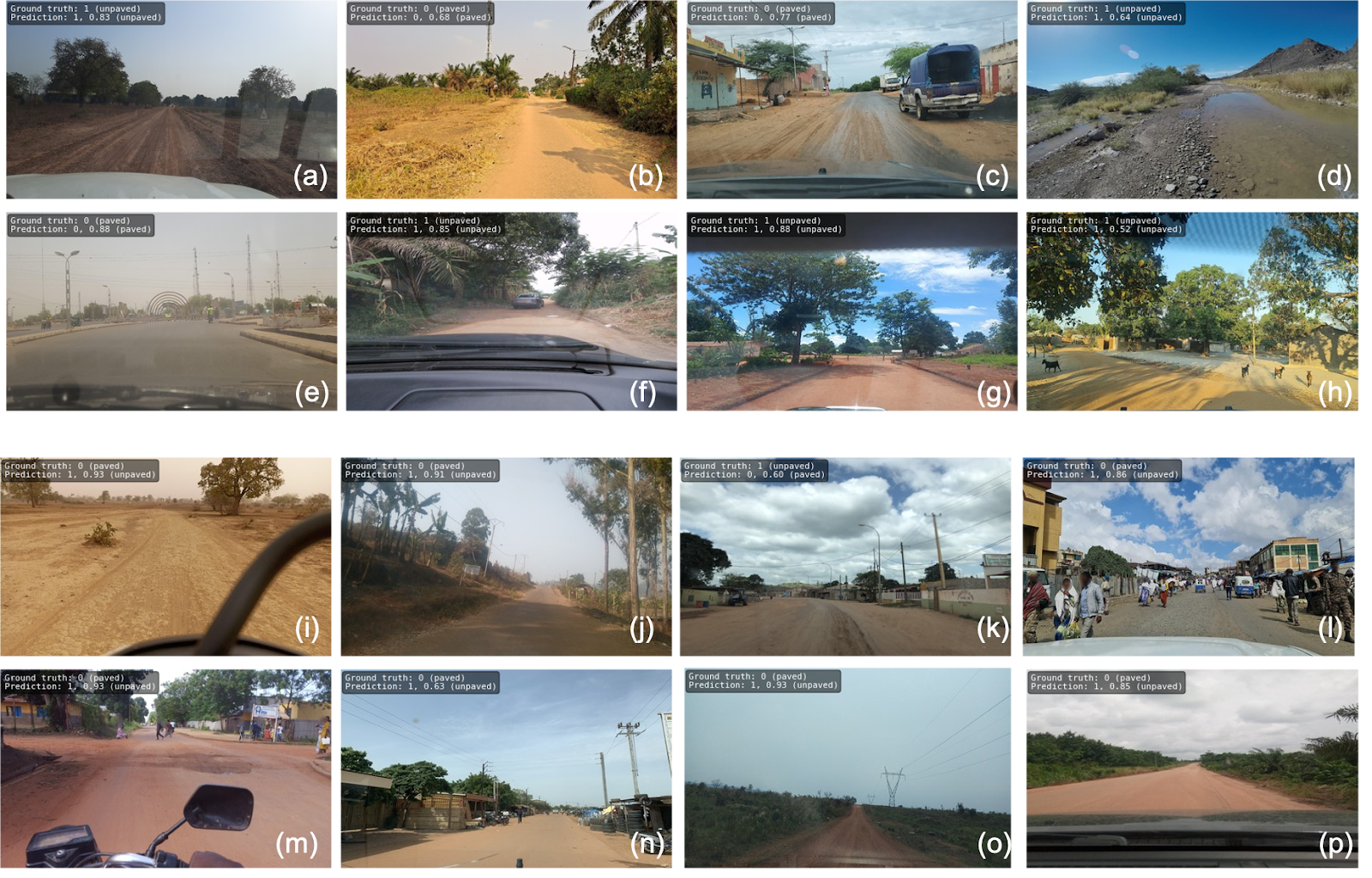
The figure above shows examples of predictions for the SWIN Transformer. Ground Truth, Prediction, and confidence score are indicated in the top left corner of each image.

The figure above shows examples of poor-quality images from Mapillary that contributed to false negative predictions in the SWIN Transformer model.
Big Data for Download, Processing, and Analytics: A Scalable Approach
At HeiGIT, we’ve leveraged tools like DuckDB and Apache Parquet to streamline data processing and enhance our deep learning pipelines.
DuckDB for High-Performance Analytics
For processing large datasets, we relied on DuckDB, an open-source SQL database management system designed for high-performance analytical queries. DuckDB excels at efficiently managing big data, allowing us to run complex queries while minimizing processing time and resource consumption.
Apache Parquet for Efficient Data Storage
To optimize data storage and retrieval, we employed Apache Parquet, an open-source, column-oriented file format that compresses data for efficient bulk processing. Parquet allows us to handle complex datasets while ensuring that both storage and retrieval processes are fast and scalable.
Downloading Global Mapillary Data
The Mapillary API provides two primary methods of accessing data: vector tiles and entity endpoints. We utilized both to download street-view images from across the globe.
The process started with creating a zoom level 8 (z = 8) map of the world, filtering out ocean areas using continent polygons. From this, we extracted tiles that contained Mapillary sequences. We downloaded a staggering 11,031,802 sequences using the tiles endpoint, where each sequence represents a series of GPS nodes linked to images. These sequences were then processed using the entity endpoint to retrieve detailed image metadata, resulting in over 2.2 billion metadata points. This enormous dataset provides the foundation for various machine learning and deep learning applications.
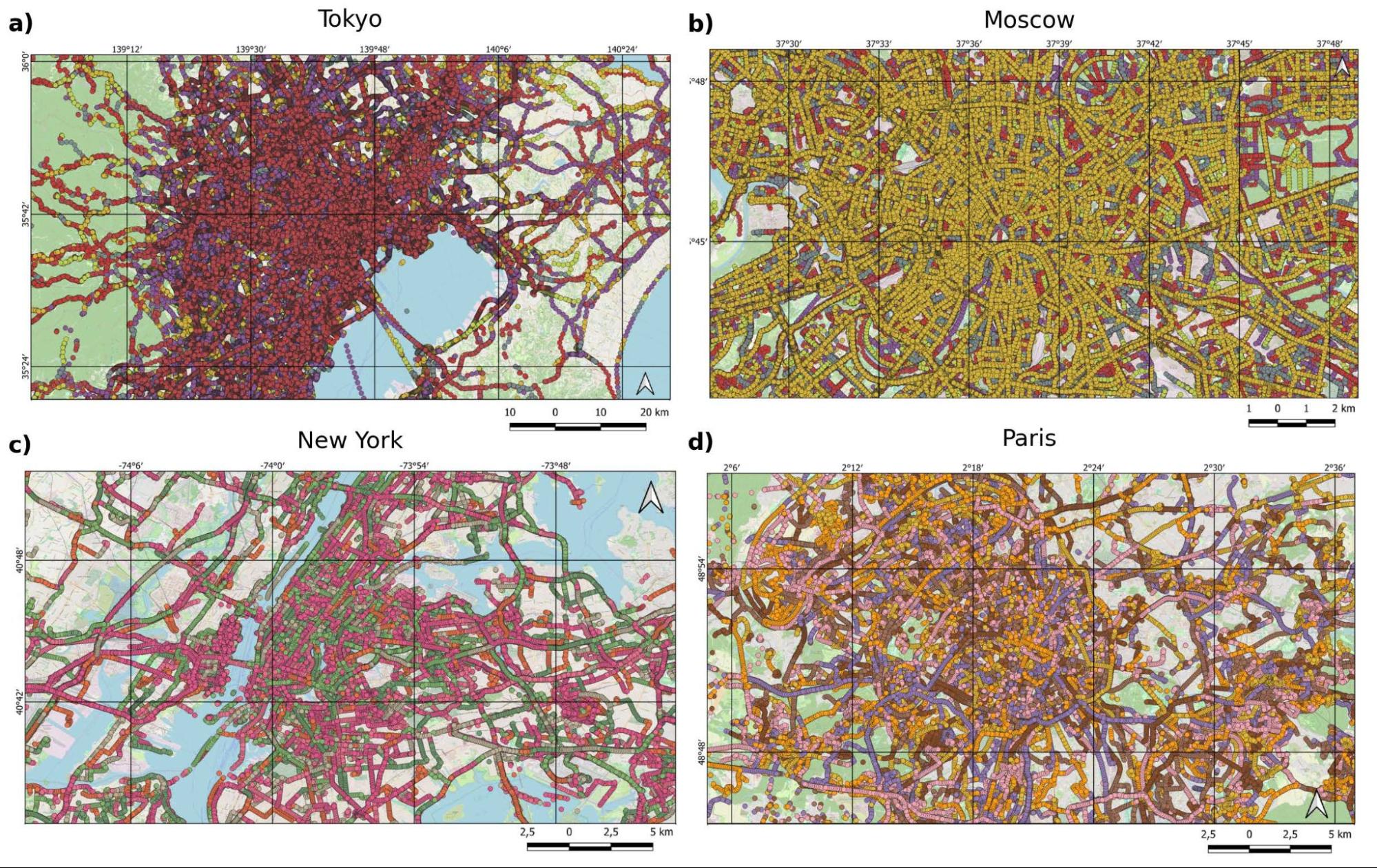
Map visualizations of road sequence data from various global urban areas. Each panel displays sequences that have been color-coded where possible, although the high volume of sequences in areas such as Tokyo and Moscow prevents distinct color coding. The different colors observed in sequences from San Francisco and Paris indicate various sequences; however, due to the limited color palette, a single color may represent multiple sequences.
Spatial Filtering for Relevant Images
Given the vast dataset, we performed spatial filtering to focus on the most relevant images for our road classification tasks. A spatial gap of 1000m for non-urban areas and 100m for urban areas was used to reduce redundancy. Urban centers were identified using two datasets:
- Africapolis for Africa.
- Global Human Settlement Layer Urban Centres Database (GHS-UCBD) for other parts of the world.
Map Matching with OSM Data
Mapillary images offer a rich potential for adding valuable attribute information to OpenStreetMap (OSM) features without needing extensive field surveys. However, due to slight inaccuracies in the geo-referencing of both datasets, we had to employ map matching techniques. Using the ohsome API, we extracted relevant OSM road objects filtered by the ‘highway’ tag based on their spatial location.
Map matching was conducted by calculating the shortest Euclidean distance between the centroid of Mapillary images and nearby OSM road segments. Images within 10 meters of an OSM road segment were directly assigned to that segment, accounting for typical GPS errors of up to 5 meters. For images farther away, additional thresholds of 20 meters and 30 meters were applied in subsequent steps.
A Confidence Index for Map Matching Accuracy
To standardize the assignment of image points to OSM segments, we developed a normalized confidence index. This index captures the contrast in distance between the nearest OSM segment and surrounding segments within a defined boundary box. The index helps ensure that each image point is confidently assigned to the most relevant OSM road segment, improving the accuracy of our spatial data processing.
Our scalable approach to big data processing, using state-of-the-art tools like DuckDB, Apache Parquet, and the Mapillary API, allows us to process and analyze vast amounts of street-view imagery efficiently. By combining these techniques with advanced map matching methods and spatial filtering, we ensure that our datasets are optimized for downstream applications like geospatial analysis.
For readers interested in deeper data insights, our latest analysis of the final dataset, available in the preprint, reveals intriguing global trends in road surfaces and Mapillary coverage, highlighting patterns in both urban and rural infrastructure.
![]()
Conclusion
As road infrastructure remains a critical metric for socio-economic development, our global road surface dataset will offer valuable insights for a wide range of applications, helping to build a more connected and resilient world.
Our road surface classification model represents a significant leap forward in global mapping and geospatial analysis. By leveraging advanced deep learning techniques, big data analytics, and crowd-sourced data, we’ve developed a model that can accurately classify roads as paved or unpaved across diverse regions and conditions. This work not only contributes to better mapping tools but also has practical applications in transportation planning, infrastructure development, and humanitarian response efforts. Routing services that cater to diverse mobility needs, such as those designed for emergency services or freight transport, benefit significantly from enriched surface type data.
The dataset generated and analyzed is openly available at the The Humanitarian Data Exchange and as a scientific preprint. If you’re interested in learning more about the data insights, check out HeiGIT’s latest blog post. We have enriched the dataset with a set of attributes with relevant Mapillary as well OSM segment information (corresponding to the OSM road segment matched to the Mapillary image point) for each image point, thereby facilitating further usage of this dataset for a variety of downstream analyses in a context of geospatial applications or then computer vision modeling benchmarking efforts.
For more details on this work, please refer to the preprint available on arXiv at http://arxiv.org/abs/2410.19874



#Featured


Next article

Bee Maps: Creating a Buzz in the World of Fresh, Affordable, and Real-Time Mapping Solutions

The Mapping Challenge
For years, the mapping industry has grappled with a significant challenge: keeping maps fresh and accurate while managing costs. We’ve all relied on methods like Google Street View-style mapping vehicles, which while effective, have proven prohibitively expensive, prompting every mapmaker to seek ways to reduce their collection budget.
Crowdsourced mapmaking projects like OSM and Waze made significant strides, but they lacked a crucial element: the ability to collect their own ground truth data. This has historically hindered their reliability and scalability.
What’s the solution? Bee Maps has been working on just that.
Enter Bee Maps
Bee Maps, powered by the decentralized mapping network Hivemapper, is addressing these challenges head-on, cracking the code of scalable crowdsourced mapping. Their approach? Sell purpose-built mapping hardware, a key differentiator and game-change in the industry.
And their device isn’t just another mapping tool: it’s a paradigm shift in how we approach geospatial data collection. They’re the fastest-growing mapping company ever, dedicated to decentralizing mapping and making map data more affordable and accessible.
Purpose-Build Hardware
While cartographers have used standard consumer consumer dashcams and smartphones for mapping, they often produce inconsistent data quality. Automotive sensors, though advanced, lack the crucial imagery needed to establish ground truth. Bee Maps dashcams bridge this gap, offering consistent quality, precise positioning, and integrated Map AI. This combination allows for accurate detections with supporting imagery, automatically signaling real-world changes.

What sets Bee Maps apart?
Bee Maps’ approach to data collection really sets it apart from the rest. Unlike projects like OSM or Waze, which rely on user-submitted information, Bee Maps passively collects its own ground truth data from its Bee dashcams, or Bees, and automatically uploads the data to the Hivemapper Network.
Since launching, contributors have passively mapped more than 28% of the world’s roads—all while going about their daily lives.
Dashcams mounted in the cars of thousands of professional drivers, such as ride-hail and delivery drivers, turn everyday trips into valuable contributions to a dynamic global map.
It’s like having a tireless cartographer in every vehicle, updating the map in real time. This continuous flow of information ensures that maps are not only current but also truly reflective of real-world conditions.
This network of dashcams continuously collects fresh data, allowing maps to be updated much more frequently than traditional methods. Collection costs are reduced by orders of magnitude by harnessing this real-time, passive data—something that has been sorely lacking in the mapping world.
By using dedicated hardware, rather than relying on smartphones, such as Mapillary, or consumer dashcams, such as Nexar, Bee Maps ensures consistent data quality and coverage. By utilizing a crowdsourced model, Bee Maps offers a more affordable alternative to traditional mapping methods, which often rely on expensive specialized vehicles.
Let’s not forget about the AI element. While automotive sensors like Mobileye can detect changes to road features and conditions, they lack the crucial imagery needed for validation. Bee Maps solves this by offering consistent quality, great positioning, and Map AI, so you can get accurate map feature detections and the imagery to back it up—automatically signaling changes in the real world.
Is this all scalable though, you might be wondering? Yes – Bee Maps stands out for its scalability.
The crowdsourced nature of passive data collection allows Bee Maps to cover vast areas quickly and cost-effectively. This decentralized approach combined with advanced processing capabilities through Map AI, results in real-time image processing, intelligent data collection focused on capturing changes, and automatic detection and placement of map features like traffic signs. This scalability means there’s no compromising in quality while covering vast areas with Bee Maps.
Growth and Industry Recognition
The numbers speak for themselves. In just two years, Bee Maps has collected an astounding 360 million total kilometers of map data. This includes 17 million unique kilometers—covering more than 28% of the world’s roads.
Bee Maps is growing five times faster than Google Street View in its earlier days. This rapid growth and innovative approach haven’t gone unnoticed in the industry. Bee Maps has created quite the buzz already with the big players taking notice too.
The team has successfully completed pilots with some of the world’s largest mapmakers and has earned the trust of highly quality-conscious customers, including automotive OEMs and autonomous vehicle developers.
Three of the largest ten global mapmakers are now using Bee Maps’ data to keep their maps fresh and accurate. This endorsement from industry giants underscores the value and reliability of Bee Maps’ solution. That’s no small feat in an industry dominated by tech giants.
A Solution for Enterprise Map Data Buyers
What excites us most about Bee Maps is its potential to democratize map data collection. By fostering an open-source map data ecosystem, Bee Maps is paving the way for innovation we’ve only dreamed of.
For the mapping experts at major enterprises – whether you’re working for tech giants like Amazon and Microsoft, logistics companies like FedEx and DHL, or automotive manufacturers like Volkswagen and General Motors – Bee Maps is offering a solution that could revolutionize your approach to geospatial data.
Traditional methods like Google can only refresh their maps once a year or every couple of years, due to the high-tech, high-cost nature of its vehicles. Hivemapper’s crowdsourced community of passive data contributors means that you are now able to access and use location data that’s got the tricky-to-find trifecta: freshness, accuracy, and affordability. For example, in an area that Google vehicles see once every 14-18 months, Hivemapper’s Bees sees that same area around 80 to 100 times a year.
It’s clear that we need fresh data as an industry and even better that it is available at a compelling price point and with a model that challenges Google’s map dominance.
Bee Maps is set to be a game-changer in streamlining workflows for mapmakers, big tech companies, transportation and logistics industries, and automotive giants. The technology is quickly establishing itself as a trusted provider in the mapping industry.
The Future of Mapping – See the World as It Is, Not as It Was.
As we look to the future, it’s clear that Bee Maps is not just participating in the mapping industry – it’s reshaping it. By bringing crowdsourced data collection through purpose-built hardware and sophisticated AI, Bee Maps is setting new standards for what’s possible in geospatial data collection.
As the company continues to expand its coverage and refine its technology, it’ll be working on continuing to deliver the world’s freshest and most accurate maps.
So, if you’re in the business of maps and you haven’t heard of Bee Maps yet, this is for you. The buzz around Bee Maps is real and they are leading the charge towards a future where our maps are just as dynamic and up-to-date as the world they represent.
Ready to join in shaping the future of mapping? Here are 5 reasons why Hivemapper built their dashcams for your mapping needs.
Did you like the article? Read more and subscribe to our monthly newsletter!

