

Melting ice sheets, precision agriculture, and satellites that operate during the night all point to the same shift: AI-powered geospatial technologies are changing how we observe, interpret, and safeguard the planet.
A Planet Under Pressure
As 2026 begins, geospatial technologies are forming a new “nervous system” for Earth, combining high-resolution satellites, AI, and digital infrastructure to track environmental change in real time.
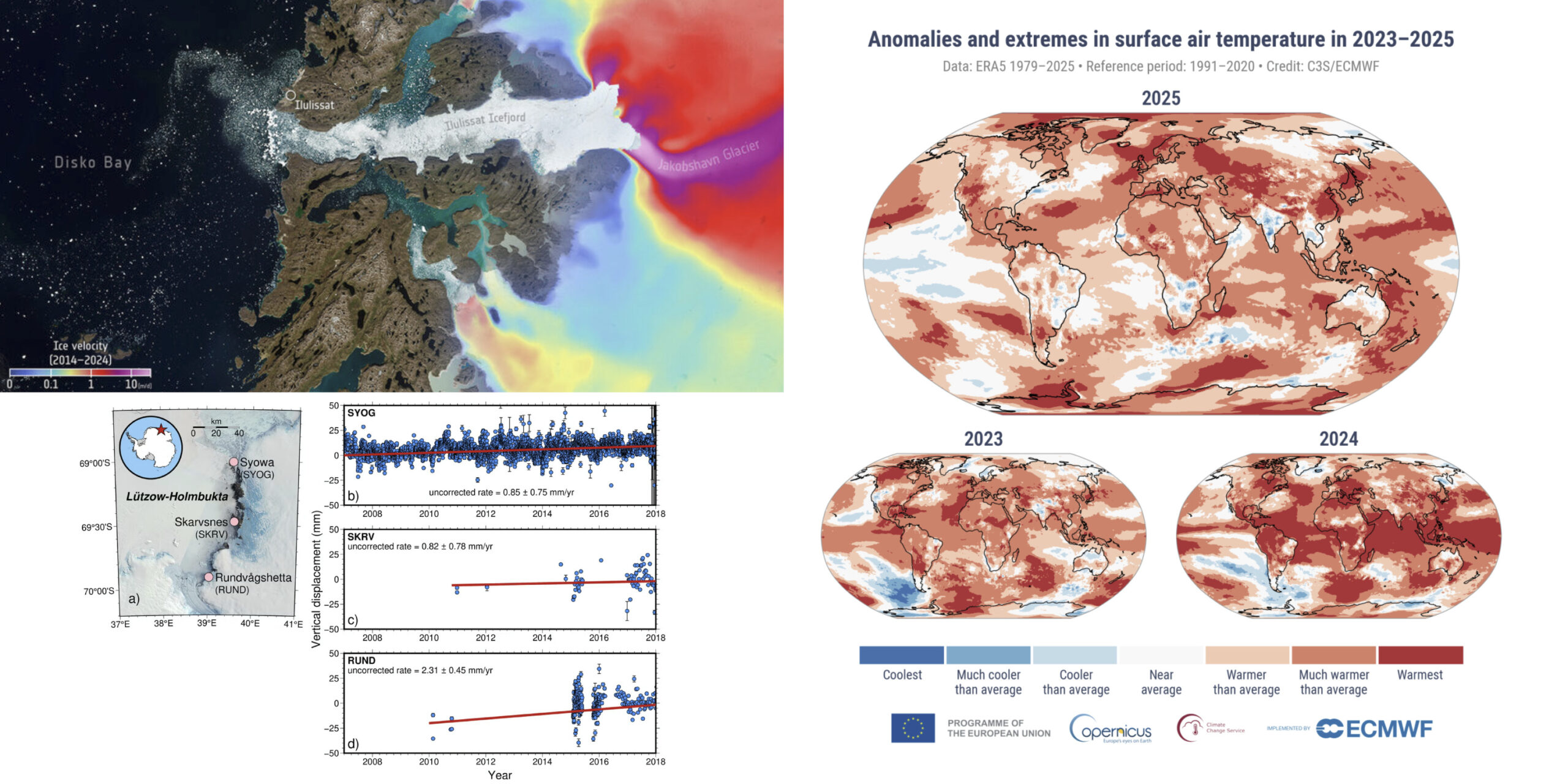
Data from the Copernicus Climate Change Service confirm 2025 as the third warmest year on record, with global temperatures 1.47°C above pre-industrial levels, and 2023–2025 marking the first three-year stretch above 1.5°C. The Arctic recorded its second-warmest year, while Antarctica reached its highest annual temperature.
Sentinel-1 satellites have provided a decade of detailed ice-flow data across Greenland and Antarctica, revealing complex dynamics. The East Antarctic Ice Sheet thinned rapidly thousands of years ago but has since re-thickened by up to 100 meters – with further context available via The Brighter Side – refining projections for future sea-level rise.
Earth Foundation Models and the Age of Spatial AI
The tools used to interpret these changes is evolving into a planetary infrastructure. The global geospatial intelligence market is projected to grow from $37.13 billion in 2025 to $62.88 billion by 2030. This growth is fueled by “GeoAI” platforms that enable automated image interpretation and predictive spatial analytics.
Central to this progress is the development of Earth Foundation Models. These AI models, documented in a recent study in Scientific Reports, are designed to be task-agnostic, learning general representations from vast reservoirs of unlabeled satellite and climate data. By prioritizing carbon-minimized operations and physical consistency, these models aim to bridge the gap between Earth observation and climate science.
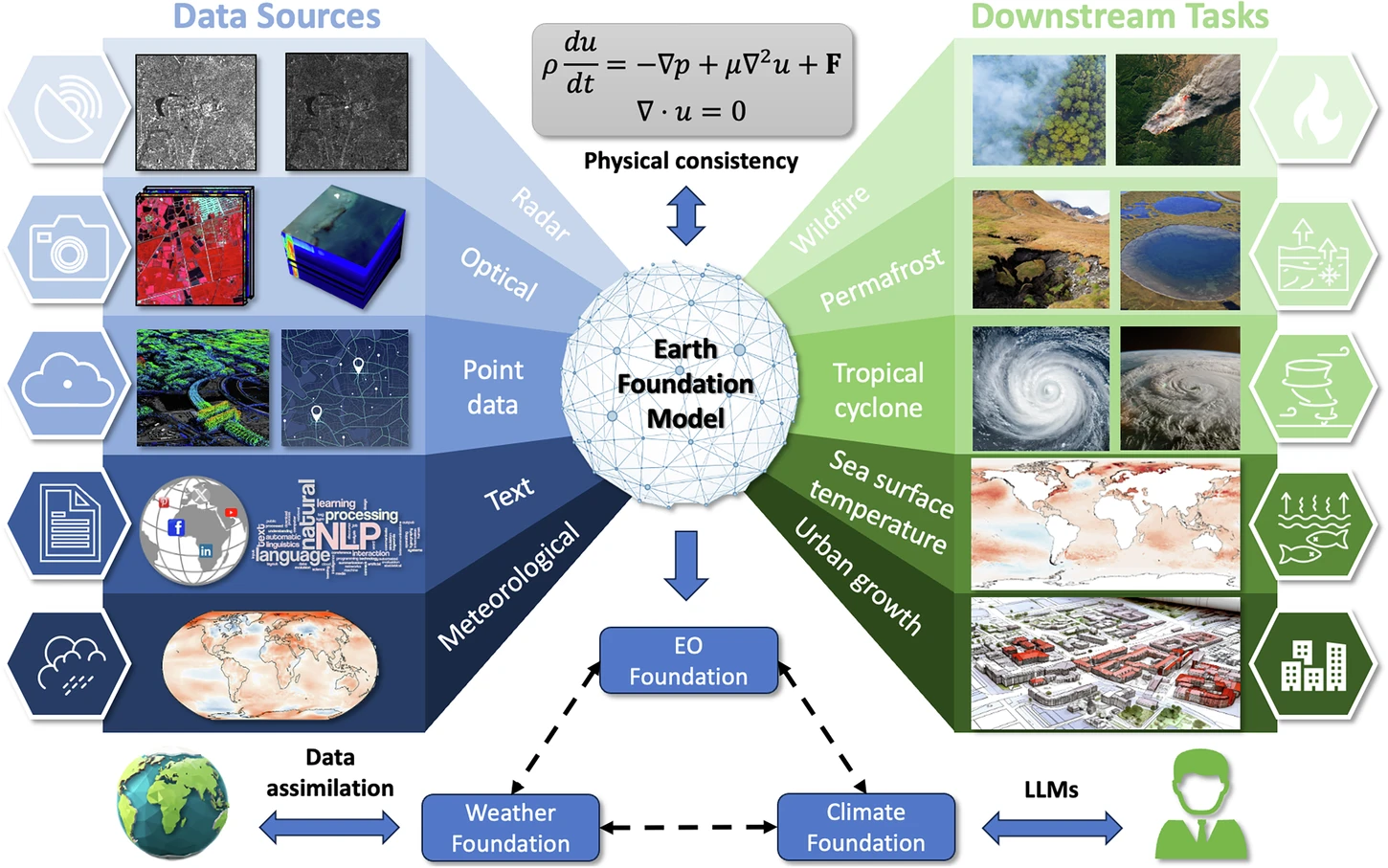
Zhu, X.X., Xiong, Z., Wang, Y. et al. On the foundations of Earth foundation models. Commun Earth Environ 7, 103 (2026). https://doi.org/10.1038/s43247-025-03127-x
Tools in Practice: Precision Agriculture and Urban Growth
Mainstream Agriculture
By 2025, over 85% of precision agriculture projects used remote sensing. Platforms like Farmonaut leverage multispectral imagery to help farmers achieve up to 30% water savings through precision irrigation and early pest detection.
Mapping Global Growth
Researchers from the Chinese Academy of Sciences recently released a high-resolution global dataset mapping city and town boundaries from 2000 to 2022. This offers evidence for monitoring urban expansion and guiding sustainable land-use planning. Accompanying tools such as ArcGIS Pro and ArcGIS StoryMaps are helping analysts communicate these findings visually.
Daily Navigation
Geospatial tools have also reached consumers directly. Google and Apple Maps now use motion-based sensors and Bluetooth to automatically save parking spots on iPhones, ensuring users never lose their vehicles in crowded lots.
Innovation in the Dark and Digital Twins
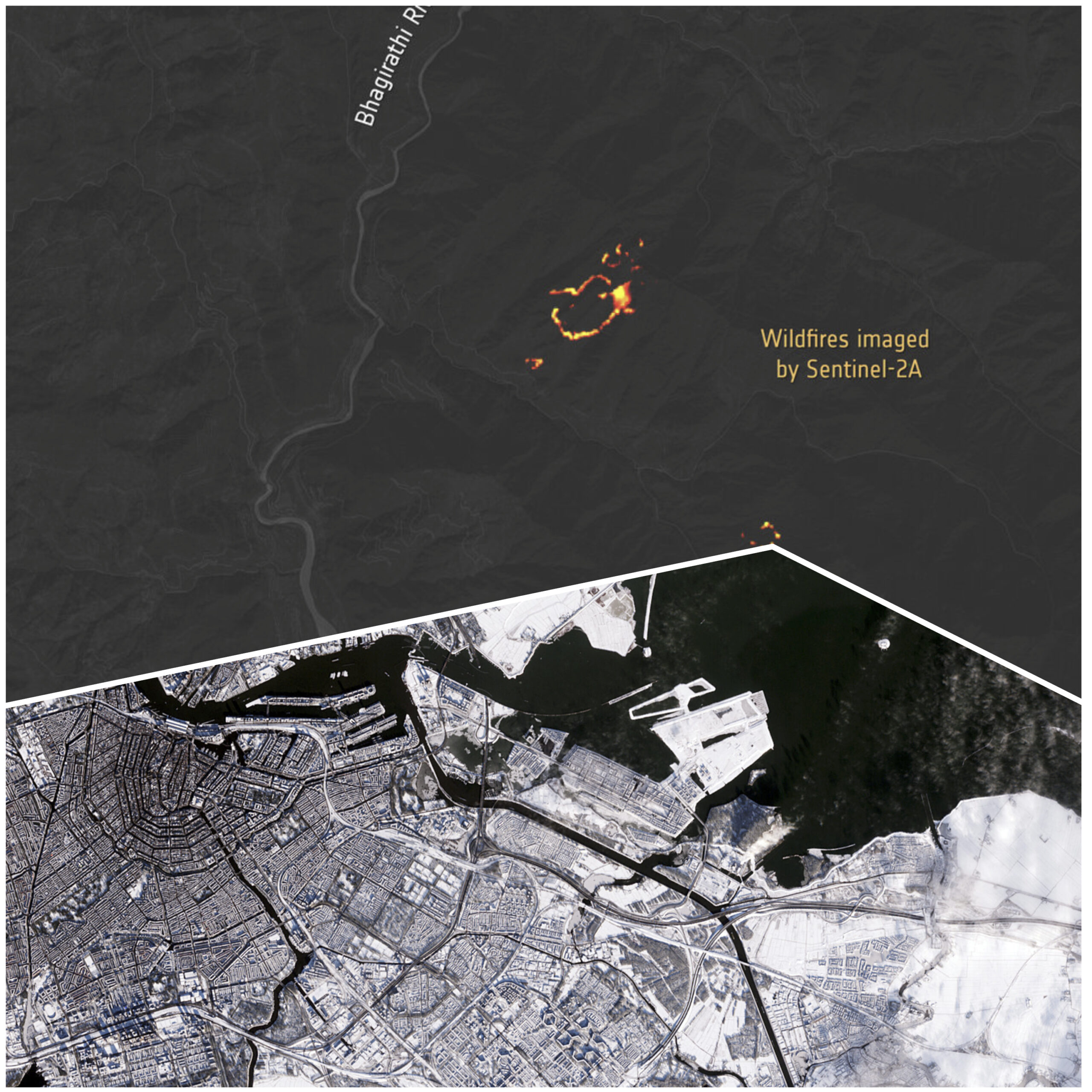
Even as the sun sets, the “eyes in the sky” remain active. The Copernicus Sentinel-2A satellite has successfully tested “night vision” capabilities, capturing imagery of gas flares in the Middle East, wildfires in India, and fishing boats off South Korea during night-time passes. A striking example of its daytime imagery also surfaced recently, with snow-covered Amsterdam captured in stunning detail from orbit.
Innoviz Technologies recently announced InnovizThree, a sensor-fusion module that combines long-range LiDAR with an RGB camera. This allows for colored 3D point clouds, purpose-built for drones and micro-robotics used in environmental monitoring. For those exploring drone alternatives following potential DJI market changes, the sensor landscape is expanding rapidly.
Meanwhile, a detailed guide to Inverse Synthetic Aperture Radar illustrates how these techniques – once military-grade – are crossing into civilian Earth-monitoring applications. The Copernicus Emergency Management Service also continues to provide rapid mapping activations for disasters worldwide.
AI Agents
AI is extending its influence beyond traditional Earth observation. he mining sector is exploring the role of AI agents in mineral exploration and processing – a field with significant geospatial overlap. Competitions like IEEC’s Earth Observation use-case ideas competition are also accelerating private-sector innovation. Community tools like open-source GIS workflows shared by researchers on social media are democratizing access to these capabilities.
A Collaborative Future
While the tools of the trade are shifting – evidenced by the closure of the nearly 37-year-old The Earth Observer newsletter in late 2025 – the mission of Earth stewardship is only expanding. New collaborative platforms like the Digital Space Ecosystem are connecting space actors and research organizations across Europe to share capabilities.
The history of cartography itself is being revisited. Ongoing debates about map projections – including the famous Mercator distortion of Greenland’s size – remind us that how we visualize the Earth shapes how we understand it. The history of cartography stretches back centuries, now accelerating into the digital age.
As we look toward 2026, the goal is clear: to move from simple observation to actionable intelligence. By integrating historical records – such as the newly scanned 18th-century wall maps at the Library of Congress – with real-time QGIS Python plugins for flood mapping and AI-driven analysis, we are building a more resilient and sustainable future. Informative video overviews, such as this tutorial of NASA Commercial Satellite Data Acquisition (CSDA) and this demonstration of GeoDelta Labs on flood mapping, are also helping practitioners get up to speed quickly.
The revolution, it turns out, is also open-source. Free tools like TVStudy and QGIS already allow anyone to map signal coverage and visualize spatial data at professional quality — a reminder that the most consequential changes in how we see our planet are not always driven by billion-dollar satellites, but sometimes by software anyone can download for free.
Did you like the news roundup? Read more and subscribe to our monthly newsletter!


#GeoAI

Next article


Imagine a model trained using ultra-high-resolution drone imagery over a small farming village. At this scale, objects like cars or tractors occupy thousands of pixels. The model learns fine details, wheels, edges, textures, and performs flawlessly. When the same model is later applied to satellite imagery covering an entire state, those same objects collapse into a few blurry pixels. The data is still correct, but the visual patterns the model learned no longer exist. This is a well-known failure mode when training on drone data and inferring on satellite imagery.
This happens because models do not learn objects in the abstract. They learn what objects look like at a specific resolution, extent, and aggregation level. Changing the scale changes the patterns, a challenge that shows up repeatedly when building and deploying geospatial AI datasets and large-area spatial mapping systems.
Scale errors are not limited to imagery. During the 2003 SARS outbreak, case data concentrated in Toronto and Vancouver were reported at the national scale. When aggregated to the country level, Canada appeared uniformly affected, triggering a nationwide travel advisory. The data itself was accurate, but the scale was wrong, as documented in SARS case reporting in Canada and later summarized in policy briefings on SARS and COVID-19. The economic cost exceeded one billion dollars.
Scale acts like a filter. Zoom out too far, and the dangerous local variation disappears. Zoom in too far, and the broader structure is lost. In geospatial AI, this is not a visualization issue. Scale directly determines what a model can and cannot learn, a point emphasized throughout AI for spatial mapping and analysis.
This article explains why scale is a decisive factor in geospatial AI. It shows how the same data can lead to different conclusions at different scales, why machine-learning models amplify scale errors, and how scale mismatches turn technical choices into real-world decision failures. It is written for geospatial practitioners, data scientists, and planners who want to understand how scale shapes model behavior, interpretation, and impact.
What “Scale” Really Means in Geospatial Analysis?
In geospatial analysis, scale is the lens through which both humans and models see the world. It defines the relationship between what is represented on a map and what exists on the ground. In GeoAI, it determines what information is visible, what gets averaged away, and what a model is physically capable of learning.
One component of scale is spatial resolution, the size of a single pixel on the ground. A 30-centimeter image can capture cars and trees, while a 30-meter image can only represent entire blocks or forests. Anything smaller than a pixel is invisible to the model, which is why understanding imagery resolution matters for how data behaves when zooming and resampling.
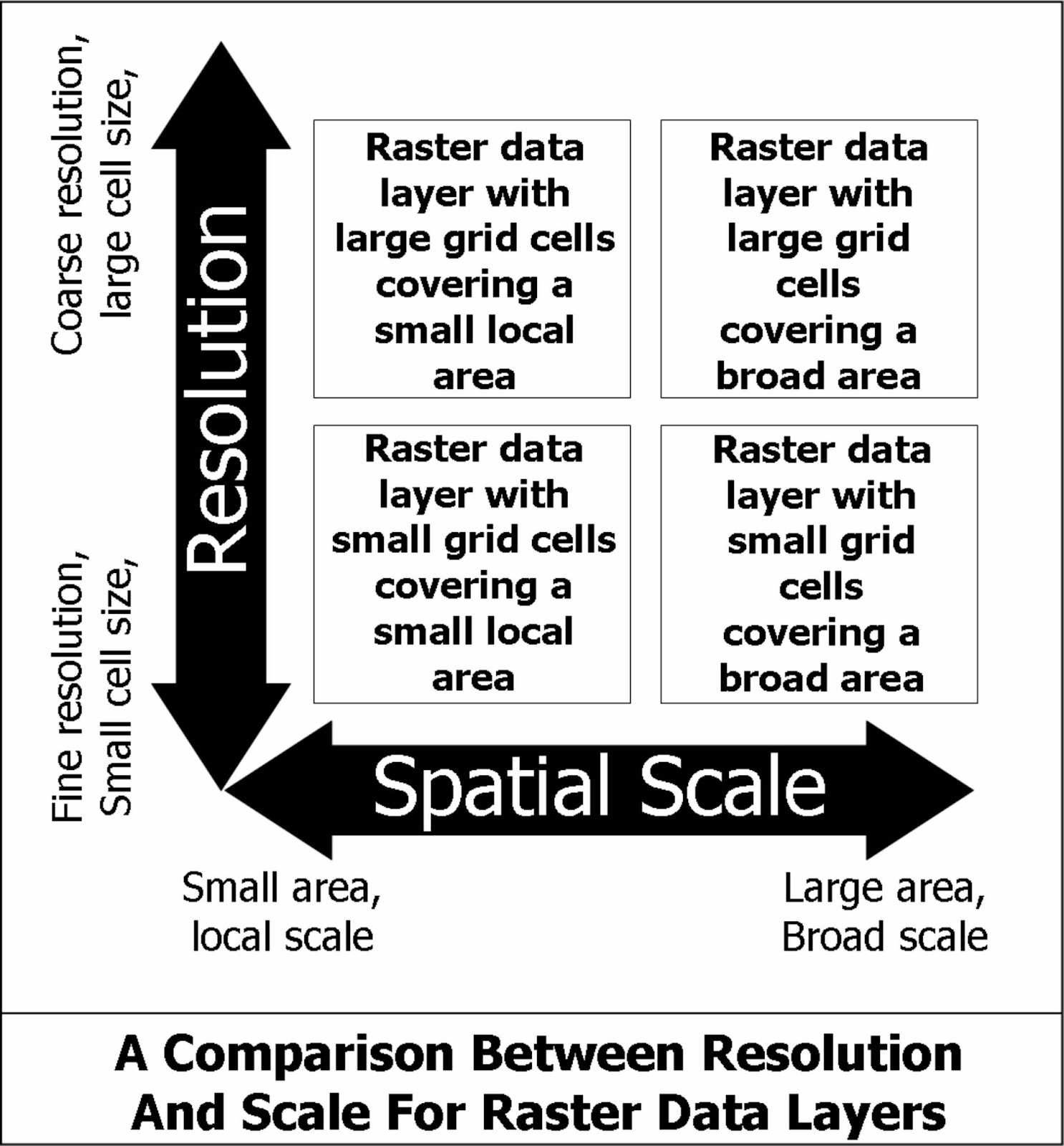
Source: GIS in Ecology
Another component is aggregation, the act of grouping fine-grained data into larger units. House-level data may be aggregated into blocks, neighborhoods, or cities. Each choice changes the result by smoothing local extremes and emphasizing broader patterns; scale and resolution in GIS fundamentally shape analytical outcomes.
Scale also includes extent, the total area being analyzed. A single building dominates the view at the street scale but becomes insignificant at the continental scale. Models trained on small extents often fail when applied to larger ones because the spatial context changes.
Finally, there is decision scale, the level at which a human needs an answer. A mayor decides at the neighborhood scale, an insurer at the parcel scale, and a climate scientist at the regional or global scale. GeoAI systems fail when the model operates at one scale while decisions must be made at another.
A common mistake is to treat scale as a visualization choice. In reality, scale is a modeling decision. Choosing a scale means deciding what counts as signal and what is discarded as noise. While maps allow endless zooming, the data itself always has a fixed resolution, and no amount of zoom can recover detail that was never captured.
Example: Same Data, Different Answers
A clear way to see how scale alters conclusions is through the Modifiable Areal Unit Problem (MAUP). The idea is simple: the outcome of a spatial analysis can change purely because of how the same data is grouped.
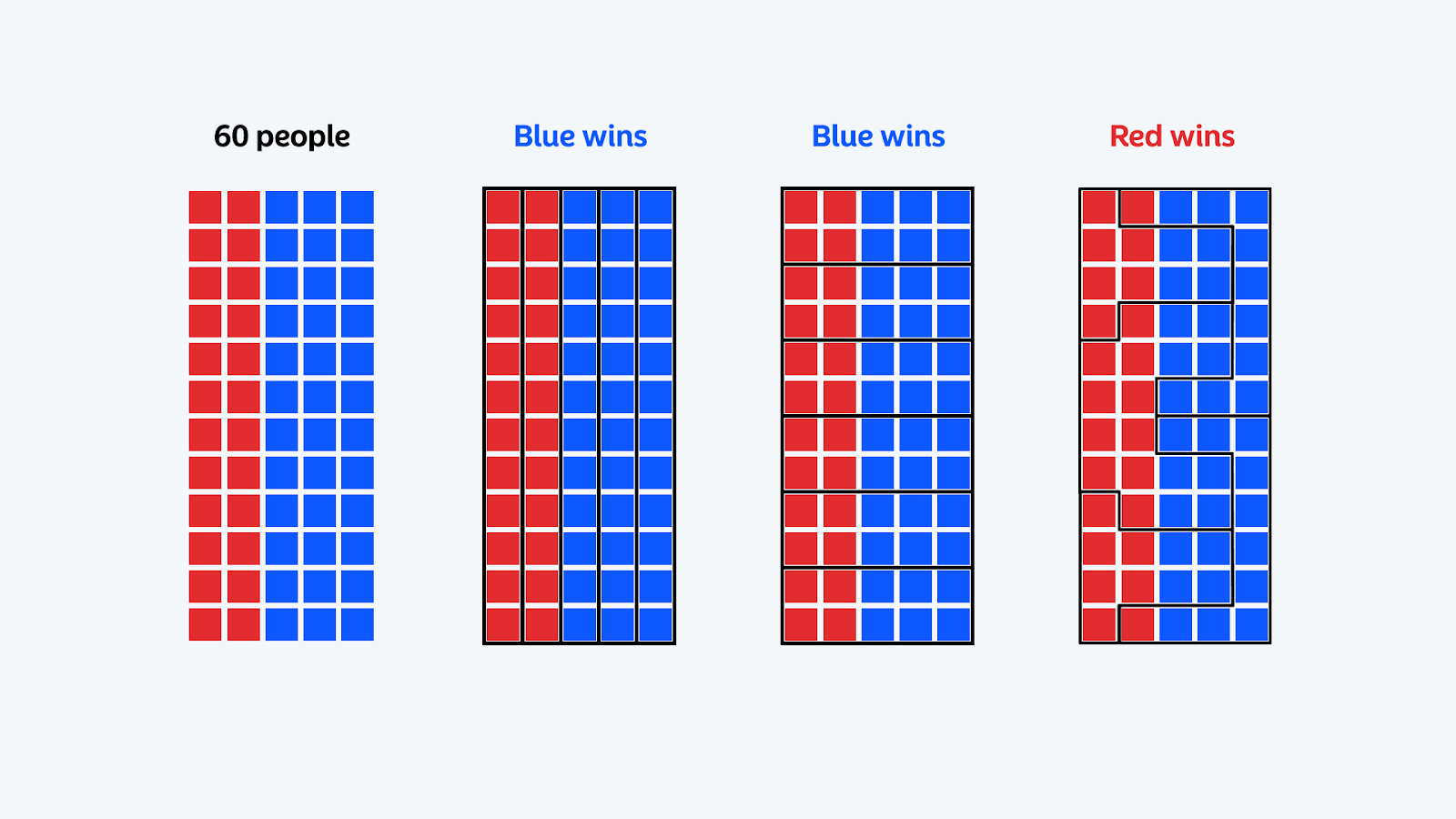
Source: Atlas
Imagine a city where you want to understand whether the education level is related to income. You have data for 1,000 people, each with years of schooling, income, and a location. At the individual level, people vary widely, and noise dominates, so any direct relationship is weak.
Now introduce a hidden spatial structure. Some neighborhoods are simply more prosperous than others. Income is influenced mostly by this neighborhood context, and only weakly by individual education. This reflects how many real cities work.
The code below demonstrates this effect. It generates synthetic people distributed across space, adds a smooth neighborhood-level prosperity gradient, and then measures the same relationship at three different spatial scales.
Output:
Individual level: 0.020
Neighborhood scale: 0.128
District scale: -0.266
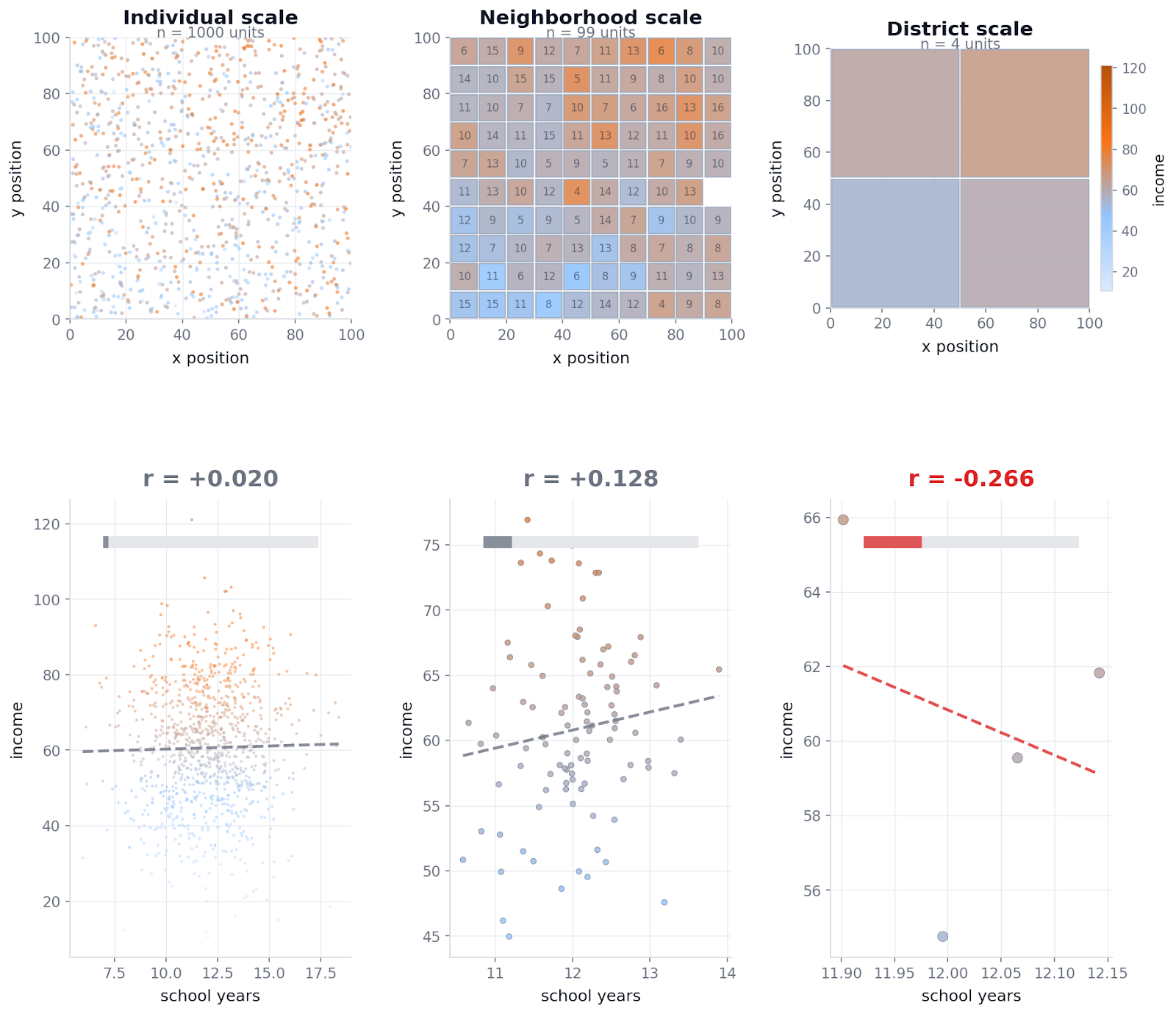
At the individual level, the relationship between education and income is essentially zero. After aggregation, the same data produces different answers. At the neighborhood scale, a weak positive relationship appears. At the district scale, so much noise has been cancelled by averaging that the remaining signal overwhelms everything, and the correlation flips sign entirely.
None of these values represent a stable truth. They are artifacts of how the data is grouped. This is the MAUP in practice. Aggregation reshapes variance, suppresses local differences, and can both exaggerate and invert statistical relationships. The input data does not change. Only the scale does.
If a decision-maker relies on a single aggregation level, they risk acting on a pattern that disappears or reverses when viewed differently. This is why scale must be tested, not assumed. Scale does not add information. It redistributes it.
Why AI Models Amplify Scale Problems?
AI models learn patterns exactly as they appear at the scale they are trained on. Unlike humans, they do not adapt intuitively when resolution, aggregation, or spatial context changes, which makes scale problems more severe in AI systems than in manual analysis.
Most models are highly sensitive to pixel size and texture. When scale changes, features blur, merge, or disappear, and the learned representation no longer matches reality. At the same time, aggregation smooths away local extremes, meaning rare but critical conditions vanish from the input entirely. This is why local variation is smoothed by aggregation, hiding the most important signals.
Another common failure occurs when training and deployment operate at different scales. Models built using expensive, high-resolution data frequently collapse when applied globally on coarser inputs, a pattern reported in geospatial dataset design.
Because AI systems produce confident outputs even when scale assumptions are violated, these errors are amplified rather than flagged. Scale mistakes become fast, precise, and expensive.
Scale in Real-World Decisions
Scale errors in geospatial AI are not abstract technical issues. They directly affect who gets protected, who pays more, and who is exposed to risk.
Flood risk is a clear example. Most official flood assessments operate at the basin or watershed scale, which works for rivers but often fails individual households. Tools like the USGS Integrated Flood Risk Management framework and recent flood exposure research show how strongly outcomes depend on local elevation and drainage, and how coarse-scale models can miss building-level risk.
Urban heat follows the same pattern. City-wide temperature averages hide extreme conditions at the block and household scales. Work on AI and GIS for urban forestry and heat mitigation and fine-grained heat vulnerability mapping shows how temperatures can vary within short distances. Programs like Sunny Lives use building-level characteristics (like roof material) to target the households most at risk.
Insurance decisions are even more sensitive to scale. Traditional underwriting relied on ZIP codes or parcel centroids, but high-precision location data for insurance shows large risk differences within a single parcel. Moving to parcel-level underwriting intelligence and location-based risk pricing supports fairer pricing and avoids excluding entire communities, a shift now central to data-driven underwriting strategies.
Across floods, heat, and insurance, the lesson is consistent: when scale is too coarse, decisions become wrong.
Making Scale Explicit, Not Invisible
Scale is one of the most powerful variables in geospatial AI, yet it is often treated as an afterthought. Model accuracy is only meaningful at the scale the model was designed for. When scale changes, performance does not slowly degrade. It often breaks.
Good practice starts with clarity. Always state the scale a model is valid at, and never apply it outside that range without testing. Just as important, the model’s scale must match the scale of the decision being made. City-level averages cannot safely guide building-level actions.
Scale should also be treated as a design choice from day one. It shapes what data is collected, what patterns a model can learn, and where it will fail. Testing across scales is not optional. It is the only way to know whether a model is robust or fragile.
As geospatial AI moves from maps to decisions, scale becomes the hidden structure behind every result. Ignoring it leads to confident but misleading outputs. Designing for it leads to systems that can be trusted.
How do you like this article? Read more and subscribe to our monthly newsletter!

