
Synthetic Data in GeoAI: Can Models Learn Without Real Data?

Geospatial AI (GeoAI) depends on data. The more examples a model sees, the better it becomes at recognizing patterns in satellite imagery, maps, and sensor data. In practice, however, high-quality geospatial training data is limited. Training modern models requires thousands or millions of labeled examples, and producing those labels is slow and expensive. Analysts often have to manually outline buildings, roads, or land-cover classes in imagery, a process known as satellite image annotation.
Even when labeled datasets exist, they are rarely perfect. Ground truth information can be incomplete or inconsistent, especially when imagery is affected by clouds, shadows, or resolution limits. Problems caused by noisy or inaccurate labels are well known in satellite imagery analysis with imperfect ground data. The challenge becomes even greater for rare events such as floods, infrastructure failures, or wildfire damage. These events do not occur frequently enough to produce large labeled datasets, yet they are exactly the scenarios where reliable GeoAI systems are needed. At the same time, privacy rules and restricted datasets limit data sharing, a challenge discussed in AI for geospatial data exploitation and GeoAI applications in environmental epidemiology.
If collecting enough real-world data is too slow, too expensive, or sometimes impossible, a natural question emerges. Can we generate the data ourselves? This article examines how synthetic environments and simulated data are being used to train geospatial AI systems. It explores when synthetic data helps, when it fails, and how it can complement real observations. The article is written for geospatial practitioners, data scientists, and GeoAI researchers who want a practical understanding of the promise and limits of synthetic data in GeoAI.
What Synthetic Data Actually Means in Geospatial Contexts
In GeoAI, synthetic data does not simply mean fake images. It refers to data generated by computers that follow the rules of geography, physics, and human behavior. The goal is to create realistic training examples when real observations are limited.
One common approach is building simulated cities and road networks, where entire urban environments are generated in 3D. Because the computer creates every building, tree, and road, the exact location of each object is already known. This means every pixel comes with a perfect label, removing the need for manual annotation.
Another form is artificial satellite imagery generated with generative models such as GAN-based geospatial image synthesis. These systems learn visual patterns from real satellite images and generate new ones that resemble forests, cities, or agricultural landscapes.

Example of GAN-generated aerial imagery. Source: Yates et al., 2022
Synthetic data can also come from physics-based simulations. Hydrological models simulate how water flows across terrain, while wildfire models reproduce how fires spread through forests. Examples include AI-assisted wildfire simulations and hybrid physics–AI hydrological modeling used to generate realistic disaster scenarios.
A fourth category involves synthetic mobility data, where virtual agents move through simulated cities to reproduce traffic and travel patterns. These agent-based models are increasingly used in synthetic mobility simulations for urban planning.
In practice, synthetic data is not meant to replace real observations. It provides additional training examples, allowing GeoAI models to learn patterns before they encounter the complexity of the real world.
Why Synthetic Data Is Attractive for GeoAI
Synthetic data is appealing because it addresses many of the challenges behind the GeoAI data bottleneck.
First, it allows researchers to study rare events. Disasters such as floods, earthquakes, or infrastructure failures occur infrequently, which means there are very few labeled examples for training models. With simulation, thousands of scenarios can be generated, allowing models to learn patterns of extreme events before they happen. This approach is increasingly explored in areas like wildfire prediction using synthetic data and AI systems for disaster-resilient infrastructure.
Second, synthetic environments allow controlled experimentation. Researchers can change one variable at a time (e.g., rainfall intensity or terrain slope) and observe how a model reacts. This level of control is impossible in real environments.
Third, simulations provide abundant labels. Because the virtual world is generated by the computer, every object already has a known identity, eliminating the need for expensive manual annotation.
Finally, synthetic datasets support large-scale pretraining. Massive simulated datasets can teach models general visual patterns before they are fine-tuned on smaller real-world datasets, an approach widely used in synthetic data pipelines for physical AI systems.
In practice, synthetic data acts like a training ground where GeoAI models can learn before confronting the complexity of the real world.
Simple Conceptual Example
Consider a simple task: training a model to detect flooded areas in drone imagery. Emergency teams could use such a system to quickly identify streets or neighborhoods that are underwater and plan safe rescue routes.
With real data, the process is slow. Flood events must first occur, drones must capture images, and analysts must manually label every flooded area in the imagery. Building a large training dataset can take years, and labeling mistakes are common.
Synthetic data offers a different approach. Instead of waiting for disasters, researchers can simulate floods using hydrological models and virtual landscapes. These simulations generate thousands of images showing how water spreads across terrain under different conditions. Because the environment is generated by the computer, the exact location of the floodwater is already known, which means every image comes with perfect labels.
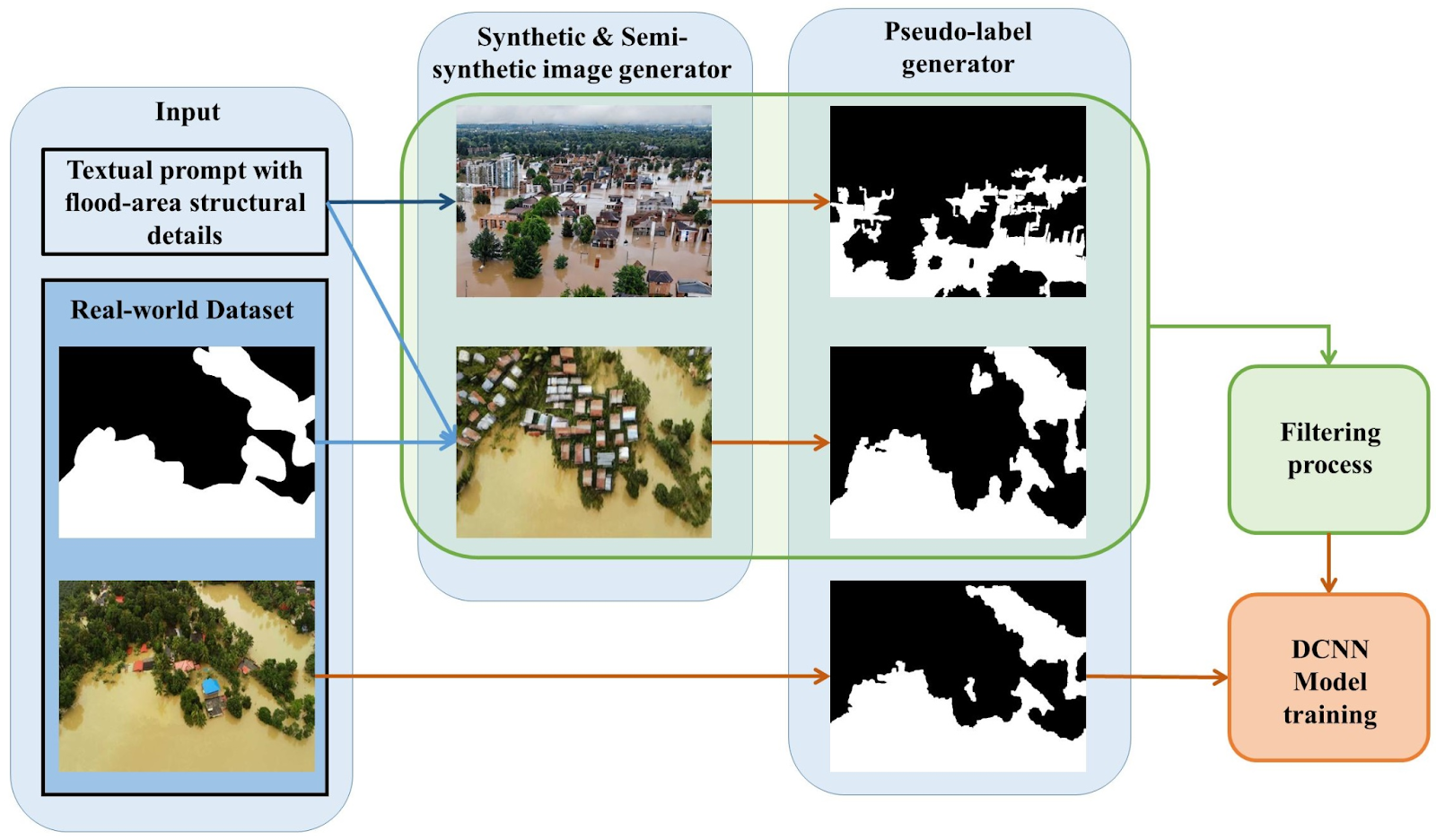
Sample Methodology using synthetic flood images. Source: Simantiris et al.,2025
The critical question remains: will a model trained on simulated floods recognize real ones? The gap between simulated and real environments is the central challenge of synthetic data in GeoAI.
The Domain Gap Problem
The biggest challenge with synthetic data is the domain gap. Synthetic environments are usually clean and controlled, while the real world is noisy and unpredictable. This difference can cause models trained in simulations to fail when applied to real imagery.
One reason is sensor and atmospheric noise. Real satellite images are affected by haze, clouds, lighting conditions, and imperfections in camera sensors. Simulated imagery often lacks these distortions, creating datasets that are unrealistically clean. Research on the simulation-to-reality domain gap highlights how models trained on perfect simulations struggle when confronted with real-world sensor noise.
Another issue is missing complexity. Simulated environments often represent idealized cities or landscapes, while real places contain irregular structures, shadows, vegetation cover, and infrastructure decay. If simulations omit these details, models may learn patterns that do not exist outside the simulator.
There is also the risk of learning simulator artifacts. Models may rely on subtle patterns created by the rendering engine instead of real geographic features. Studies examining the gap between synthetic and real-world imagery show how these artifacts can distort model behavior.
To reduce this gap, researchers often apply techniques like domain randomization and domain adaptation, intentionally adding noise and variability so models learn more robust features.
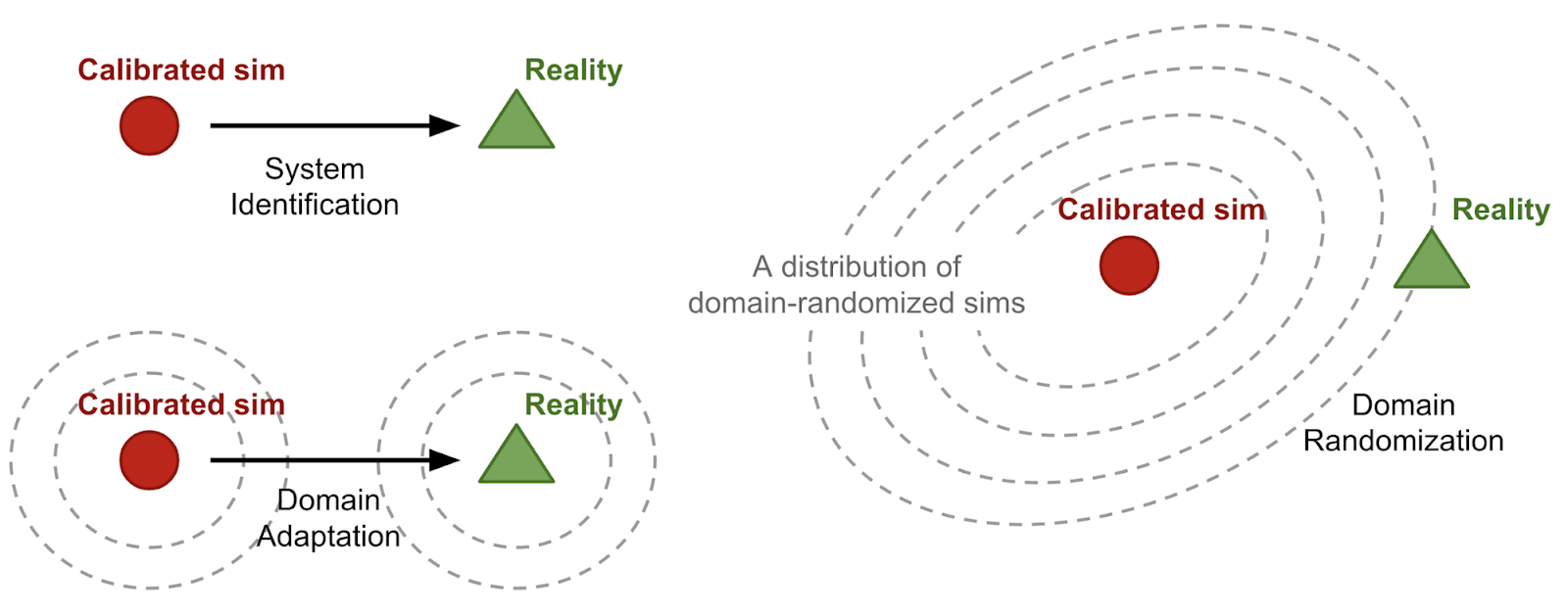
Domain Randomization. Source: Lil’Log
Where Synthetic Data Actually Works Well
Despite the domain gap, synthetic data already performs well in several GeoAI applications when used carefully. One of the most effective uses is pretraining and augmenting rare classes. For example, models designed to detect hurricane damage often lack large labeled datasets. Synthetic augmentation can generate thousands of variations of damaged buildings, helping models learn patterns before encountering real disaster imagery.
Synthetic environments also work well for learning structural patterns, such as road networks. Training on simulated urban layouts allows models to understand how roads typically connect and intersect, which improves performance when extracting roads from satellite imagery in rapidly growing cities.
Another important application is infrastructure resilience modeling. Engineers increasingly build digital twins of cities and simulate floods, earthquakes, or infrastructure failures to identify vulnerable assets before disasters occur.
Synthetic data has also shown strong results in perception systems. NVIDIA demonstrated that simulated imagery can improve the detection of distant vehicles in autonomous driving systems, achieving significant gains in accuracy in synthetic far-field object detection experiments.
Finally, synthetic augmentation is helping map complex urban environments. Methods such as SAMLoRA-based extraction of informal settlements use small real datasets combined with generated examples to improve the detection of dense informal neighborhoods.
In these cases, synthetic data does not replace real observations. It strengthens them.
Hybrid Futures: Blending Simulation and Reality
The future of GeoAI is unlikely to rely on synthetic data or real observations alone. The most effective systems increasingly combine both. Synthetic data provides scale and flexibility, while real data keeps models grounded in reality.
One common approach is fine-tuning synthetic-pretrained models. Models are first trained on large synthetic datasets to learn general visual patterns, then refined using smaller real-world datasets. This strategy reduces the need for large labeled datasets while improving performance in real environments.
Another promising direction involves physics-informed neural networks, which incorporate physical constraints directly into the learning process. These models ensure predictions remain consistent with real-world processes such as fluid flow or energy conservation, an idea explored in physics-informed neural network frameworks and broader PINN research literature.
Researchers are also exploring simulation-in-the-loop training, where models interact with simulators during training and continuously improve through feedback. Combined with techniques such as domain adaptation, which helps models transfer knowledge from synthetic to real environments, these methods aim to bridge the gap between simulated and real data.
In practice, the future of GeoAI is not synthetic versus real. It is synthetic plus real.
What This Means for the Future of GeoAI
Synthetic data is becoming an important part of the GeoAI toolkit. It allows researchers to generate training data for rare events, test new scenarios, and explore environments that would be difficult or impossible to observe in the real world. Simulated environments also open the door to new types of systems that can experiment with urban planning, disaster response, or environmental change before decisions are implemented.
At the same time, synthetic data cannot replace reality. Models must remain grounded in real observations and validated against real-world measurements. If training relies too heavily on simulated environments, models risk drifting away from the complexity and unpredictability of actual geography.
Future GeoAI systems will likely combine simulations, physical models, and real data into integrated environments where planners and researchers can test ideas safely before applying them in practice. These systems will make it easier to study rare disasters, evaluate infrastructure resilience, and explore how cities respond to environmental change.
Synthetic data expands what we can imagine and simulate. Real-world data keeps those simulations honest.
If we combine both responsibly, GeoAI will not only help us understand the world. It will help us prepare for futures that have not happened yet.
Further Resources:
- https://www.youtube.com/watch?v=HIusawrGBN4
- https://www.youtube.com/watch?v=0LWurOJlIAY
- https://www.tandfonline.com/doi/full/10.1080/13658816.2025.2609806
- https://www.sciencedirect.com/science/article/pii/S2666378324000308
- https://www.meegle.com/en_us/topics/synthetic-data-generation/synthetic-data-for-geospatial-analysis
Did you like this post? Read more and subscribe to our monthly newsletter!


#Contributing Writers

Next article

1. Iran at a glance

With a population of roughly 92 million people, Iran is one of the largest countries in the Middle East and ranks among the top twenty countries globally by both population and land area. Iran’s nominal GDP is approximately $418 billion, placing it around 36th in the world by economic size. Despite economic pressure from sanctions, the country maintains a relatively moderate unemployment rate of about 7.2 percent.
Iran also has a high literacy rate, with around 89 percent of adults able to read and write, while youth literacy approaches 99 percent. However, educational outcomes still vary between urban centers and rural regions. The country possesses vast hydrocarbon resources. Iran is among the world’s largest energy producers, ranking ninth globally in oil production and third in natural gas production, making energy exports a central pillar of its economy.
source: Al Jazzera
2. How big is Iran?
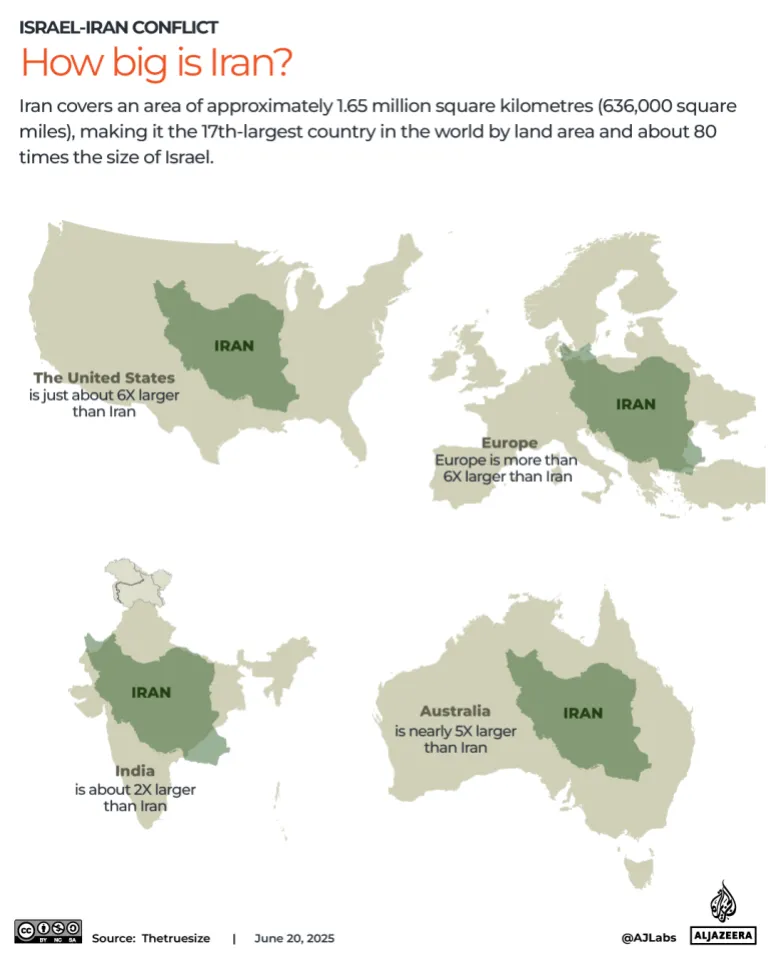
Located in Western Asia, Iran is the second-largest country in the Middle East after Saudi Arabia and the 17th-largest country in the world, covering approximately 1.65 million square kilometres (636,000 square miles). Iran shares land borders with seven countries. Its longest border is with Iraq, followed by Turkmenistan, Afghanistan, Pakistan, Azerbaijan, Türkiye, and Armenia, reflecting its strategic position at the crossroads of the Middle East, Central Asia, and the Caucasus.
To put its size into perspective, Iran’s territory is about one-sixth the land area of the United States and is roughly comparable in size to the U.S. state of Alaska. Globally, Iran is about one-sixth the size of Europe, around one-fifth the size of Australia, roughly half the size of India, and about 80 times larger than Israel, illustrating the scale of the country within the Middle Eastern region.
source: Al Jazzera
3. Demographics of Iran
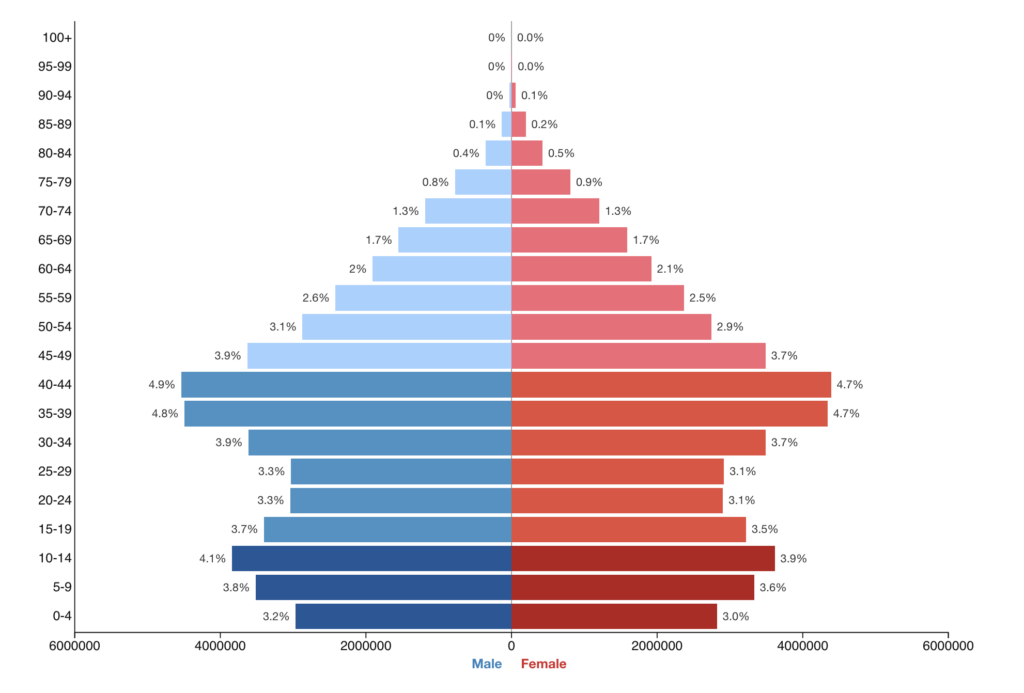
Iran has a relatively young population. Nearly 60 percent of Iranians are under the age of 39, according to data from the United Nations Statistics Division. The country’s median age is around 33–34 years, reflecting a society shaped largely by the post-revolutionary era. At the same time, about 77 percent of the population lives in urban areas, highlighting the strong shift toward city-based economies and lifestyles.
The largest age cohorts are those aged 30–34 and 35–39, meaning a significant share of the population was born after the 1979 Islamic Revolution, which overthrew the Pahlavi monarchy and reshaped Iran’s political and social system.
In recent years, however, Iran has experienced notable emigration of educated professionals, driven largely by economic pressures, limited career opportunities, and political uncertainty. This “brain drain” has become an important demographic and economic challenge for the country.
source: Wikipedia
4. What are Iran’s ethnicities?
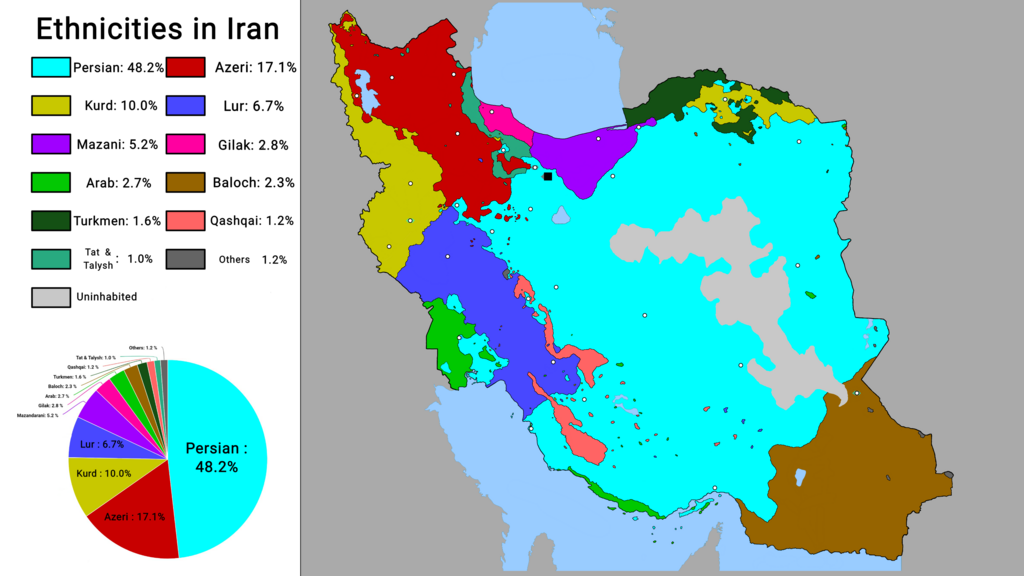
Iran is an ethnically and culturally diverse country. Persians make up about 61 percent of the population, while several large minority groups contribute to the country’s social fabric. These include Azerbaijanis (around 16 percent) and Kurds (about 10 percent), along with Lurs (6 percent), Arabs (2 percent), Baloch (2 percent), and other Turkic groups (around 2 percent).
Religiously, Iran is predominantly Shia Muslim, with about 90 percent of the population following Shia Islam, which is also the official state religion. Sunni Muslims and other Muslim sects account for roughly 9 percent of the population.
The remaining about 1 percent belongs to recognized religious minorities, including approximately 300,000 Baha’i, 300,000 Christians, 35,000 Zoroastrians, 20,000 Jews, and around 10,000 Sabean Mandeans, according to data from the Minority Rights Group. These communities represent some of the oldest religious traditions in the region.
source: Wikipedia
5. Top tourist attractions in Iran
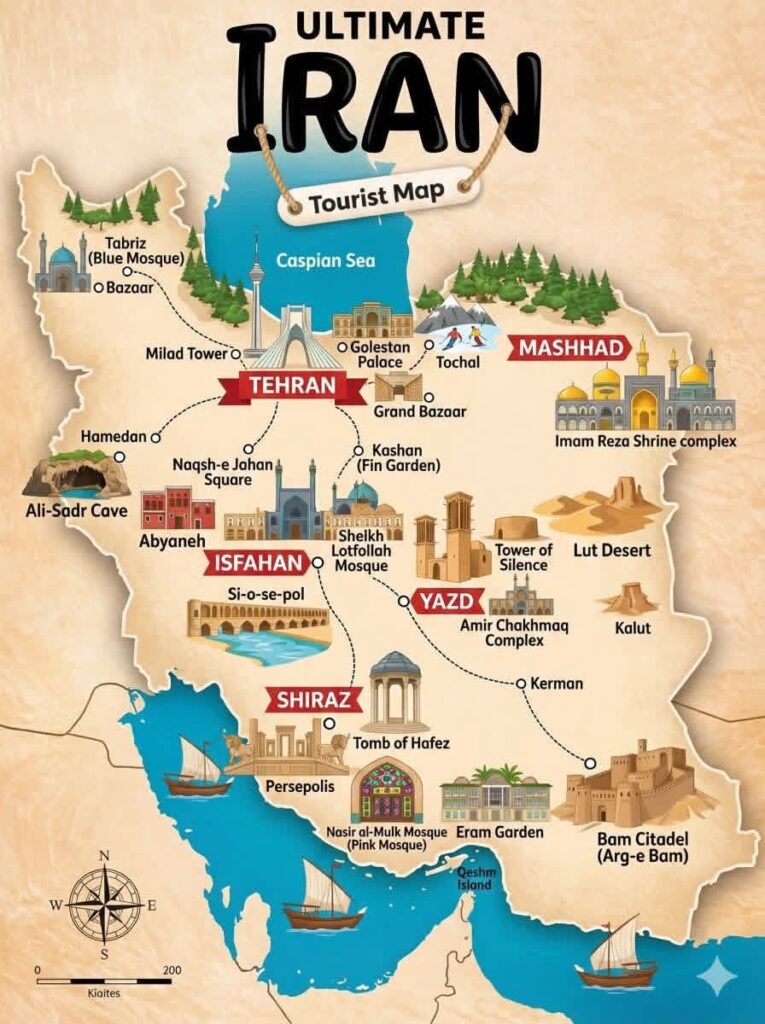
Iran offers a rich mix of historical cities, ancient ruins, religious sites, and natural landscapes that reflect more than 2,500 years of Persian civilization. Some of the country’s most famous destinations include Tehran, the modern capital and political center; Isfahan, known for its Safavid-era architecture and the monumental Naqsh-e Jahan Square; Shiraz, famous for Persian poetry, gardens, and nearby ruins of Persepolis, the ceremonial capital of the ancient Persian Empire.
Other important cultural destinations include Yazd, a desert city known for its windcatchers and Zoroastrian heritage, and Mashhad, home to the Imam Reza Shrine, one of the holiest pilgrimage sites in Shia Islam. Historic towns such as Kashan preserve classic Persian garden architecture, while sites like the Bam Citadel illustrate Iran’s long history along the Silk Road.
Iran’s natural landmarks are equally diverse. The Lut Desert, one of the hottest places on Earth, features dramatic rock formations and vast sand dunes, while mountainous areas such as Tochal near Tehran attract visitors for skiing and hiking. Along the Persian Gulf coast, islands such as Qeshm offer unique geological landscapes and marine ecosystems.
Together, these destinations highlight Iran’s cultural depth, blending ancient Persian heritage, Islamic architecture, and diverse natural environments.
source: FB
6. Internet freedom in Iran
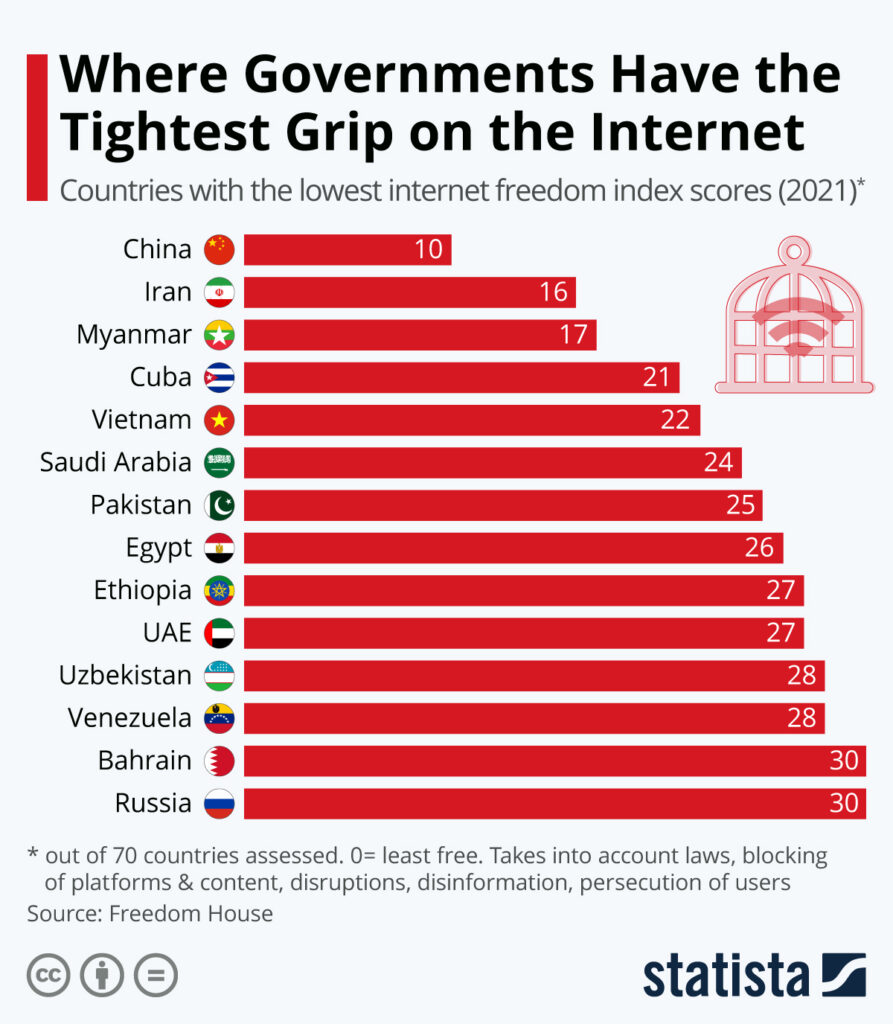
According to the Freedom House Freedom on the Net index, Iran is among the countries with the lowest levels of internet freedom in the world. In the 2025 report, Iran scored 13 out of 100, placing it firmly in the “Not Free” category and ranking near the bottom globally. Authorities heavily restrict access to the internet by blocking major platforms such as Facebook, YouTube, and X, filtering thousands of websites, and monitoring online activity. The government also promotes a domestic “National Information Network”, which allows tighter control over content and surveillance of users. Compared with most countries, Iran’s online environment is therefore highly restricted—only China scores lower in some global comparisons, highlighting the extent of state control over digital information and communication.
source: Freedom house
7. Iranian Diaspora Around the World
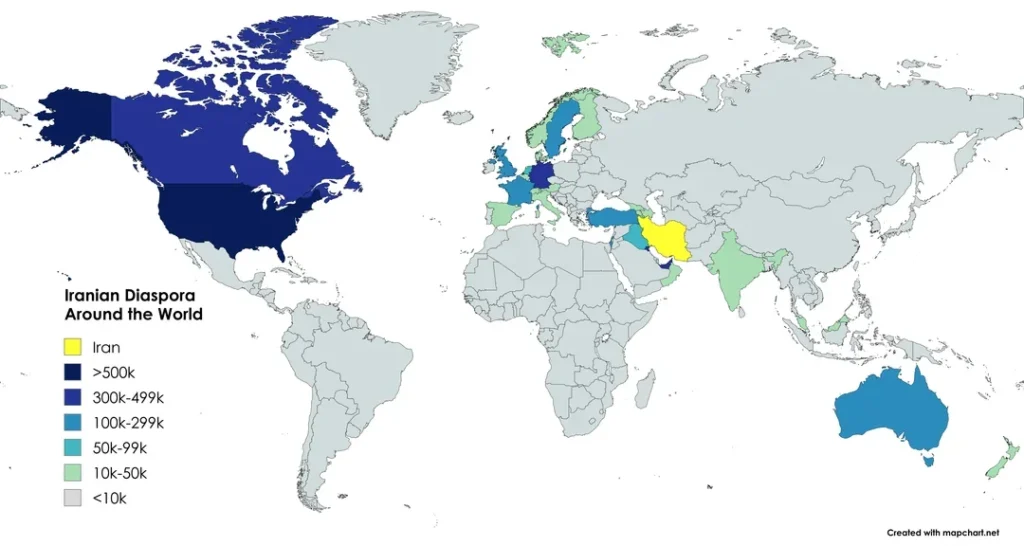
The map highlights the global distribution of the Iranian diaspora, which has grown significantly over the past decades due to political upheavals, economic challenges, and migration following the 1979 Islamic Revolution. The largest Iranian communities live in the United States and Canada, each hosting well over 500,000 people of Iranian origin. Significant populations are also found across Europe—particularly in Germany, the United Kingdom, and Sweden—as well as in Australia and the Gulf region. Many members of the Iranian diaspora are highly educated professionals working in fields such as technology, medicine, academia, and business. Today, the global Iranian community plays an important role in shaping international perceptions of Iran and maintaining cultural and economic ties between the country and the wider world.
source: Reddit
8. The Iranian Revolution: A timeline

Key data/figures: 1979 revolution; 40+ years of post‑revolution state evolution.
Why it matters (context): Use this as the narrative “starting pistol”: the revolution remade Iran’s state ideology, foreign policy posture, and security institutions—setting the baseline for recurring confrontations with the US and key regional rivals. It frames later charts (sanctions, nuclear programme, proxy network) as downstream consequences of the post‑1979 system.
source: Al Majalla
9. Iran 1979–2025: A Timeline of Crises and Turning Points

The Iran has faced recurring political, military, and economic crises since the Iranian Revolution established an Islamic republic. Soon after the revolution, tensions with the United States erupted during the 1979–1981 hostage crisis, followed by the devastating Iran–Iraq War that killed hundreds of thousands and militarized the country. In the decades that followed, Iran experienced repeated challenges including leadership transitions after the death of Ayatollah Khomeini, destructive earthquakes, waves of domestic protests, and escalating confrontation with Western powers over its nuclear program. From the 2000s onward, international sanctions and cyberattacks intensified pressure on Iran’s economy, while regional conflicts—especially its involvement in Syria and tensions with Israel and Gulf states—deepened geopolitical isolation. Periodic nationwide protests driven by economic hardship and political repression have further shaken the country, illustrating how internal unrest, sanctions, and regional rivalries have continuously shaped Iran’s political trajectory.
source: Al Jazzera
10. What is the status of Iran’s nuclear programme?
![]()
Over the past two decades, a series of milestones has brought Iran’s nuclear program to a critical moment. International concern intensified in the early 2000s as Iran expanded uranium enrichment, leading to sanctions and years of negotiations. In 2015, a landmark agreement between Iran and world powers temporarily restricted enrichment activities and introduced international inspections in exchange for sanctions relief. However, the framework gradually eroded after the United States withdrew from the deal in 2018 and Iran began expanding enrichment and stockpiling uranium beyond the agreement’s limits. By the mid-2020s, Iran had accumulated the technical capacity to approach nuclear-weapon “breakout” within a short timeframe. The timeline reaches a decisive point in 2025, when key mechanisms linked to the 2015 agreement—including the ability to automatically reimpose UN sanctions—approach expiration, forcing governments to decide whether to revive diplomacy, increase pressure, or risk further escalation around Iran’s nuclear ambitions.
source: LFI
11. GDP of Iran
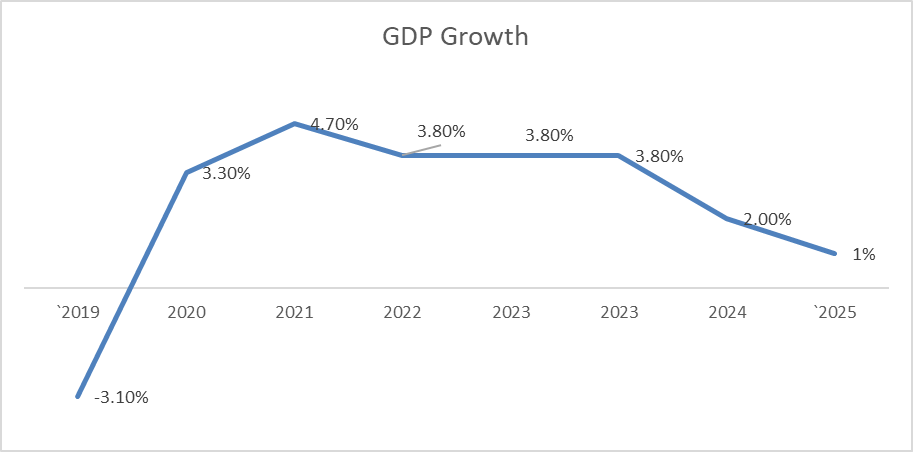
Iran’s economy has struggled in recent years under the combined pressure of international sanctions, high inflation, and structural economic weaknesses. According to analysis by the Clingendael Institute, Iran’s nominal GDP is expected to fall below $400 billion, reflecting weak economic performance and currency depreciation. While the economy recorded around 4 percent growth in local currency terms in the year ending March 2024, the value of the economy in U.S. dollars has largely stagnated due to the sharp decline of the Iranian rial. Structural problems such as large budget deficits, energy shortages, corruption, and lack of investment continue to constrain growth, while sanctions remain the most important external factor limiting trade, financial access, and foreign investment. Despite these challenges, the economy shows some resilience thanks to its diversified structure: the service sector contributes more than half of GDP, while petroleum accounts for about 16 percent, highlighting Iran’s continued reliance on energy exports.
source: Clingendael
12. Iran’s crude oil production
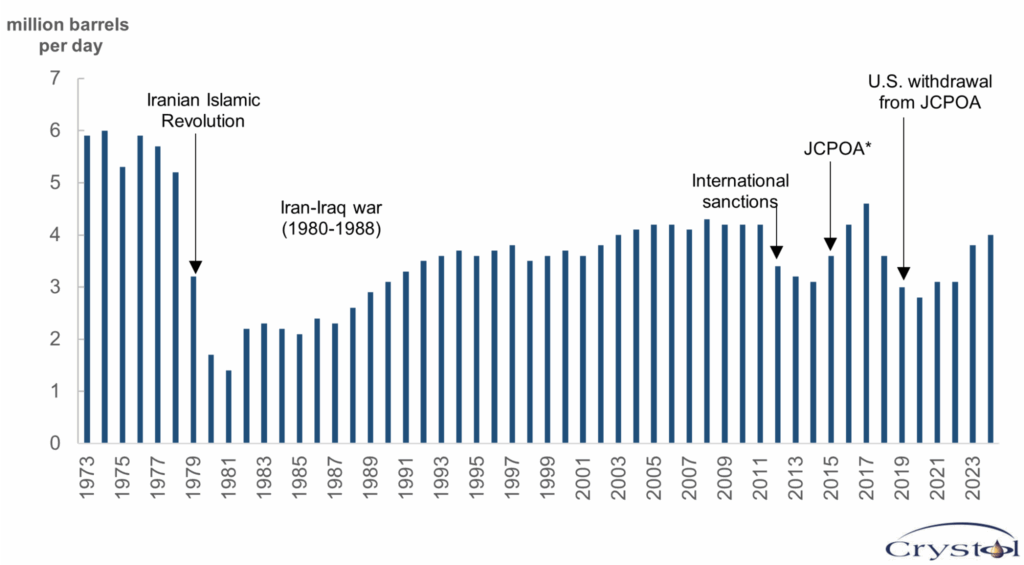

Iran remains one of the world’s major oil producers despite decades of international sanctions. The country currently produces around 3.2–3.3 million barrels of crude oil per day, according to OPEC and CEIC data, placing it among the largest producers in the Middle East and one of the top producers within OPEC. Production has fluctuated significantly over the past two decades: it reached nearly 4 million barrels per day in 2005, fell sharply during periods of sanctions—dropping to around 1.9 million barrels per day in 2020—and has gradually recovered in recent years. Iran holds some of the largest oil reserves in the world, and the oil sector remains a strategic pillar of its economy and geopolitical influence, even though sanctions have limited foreign investment and reduced its share of global oil markets.
source: CEIC , Crystol Energy
13. Iran’s Economy Under Sanctions: The High Cost of Isolation
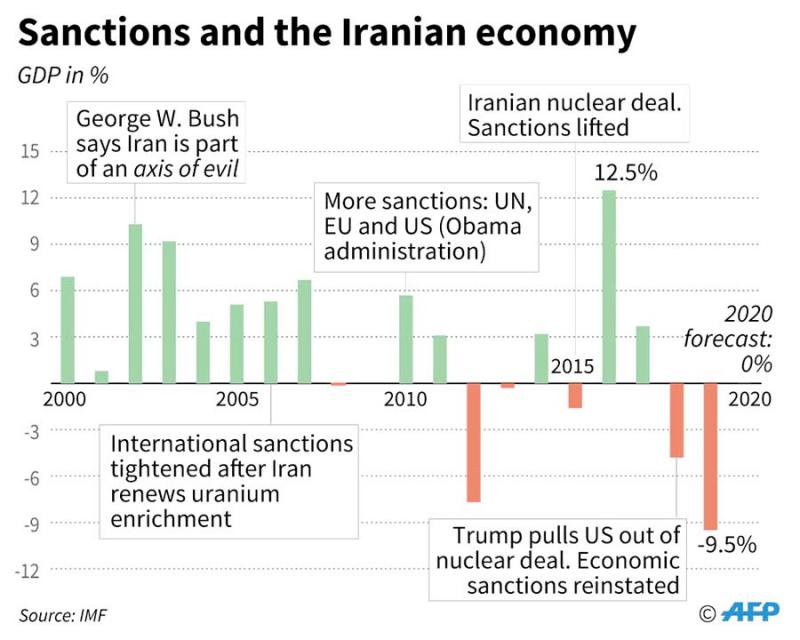
U.S. economic sanctions have imposed heavy costs on Iran’s economy by sharply reducing oil exports, limiting access to global finance, and discouraging foreign investment. Since the re-imposition of sanctions, Iran’s crude exports reportedly dropped from about 2.5–2.7 million barrels per day to roughly 250,000–400,000 barrels per day, cutting deeply into government revenues. Iranian officials estimate that sanctions have cost the country around $100 billion in lost oil income and another $100 billion in foreign investment and credit, weakening the national currency and contributing to inflation and economic hardship. The restrictions are designed to pressure Tehran over its nuclear and regional policies, but they have also strained everyday economic activity inside the country while forcing Iran to seek alternative trade channels and adapt its economy to prolonged isolation.
source: The Arab Weekly
14. Strait of Hormuz: volumes and alternatives


The Strait of Hormuz is one of the most critical chokepoints in the global energy system. Located between Iran and Oman, the narrow waterway connects the Persian Gulf with the Gulf of Oman and the Arabian Sea, serving as the main export route for oil produced in Gulf countries. According to the U.S. Energy Information Administration, roughly 20 million barrels of oil per day—about one-fifth of global petroleum consumption—passes through the strait, making it the world’s most important oil transit chokepoint. In addition to crude oil, significant volumes of liquefied natural gas (LNG) also move through the passage, particularly from Qatar. Because such a large share of global energy supply depends on this narrow route, any disruption—whether from conflict, military tensions, or blockades—could have immediate consequences for global oil prices and international energy security.
source: EIA
15. Iran and the Middle East: Competing Alliances and Regional Battle Lines
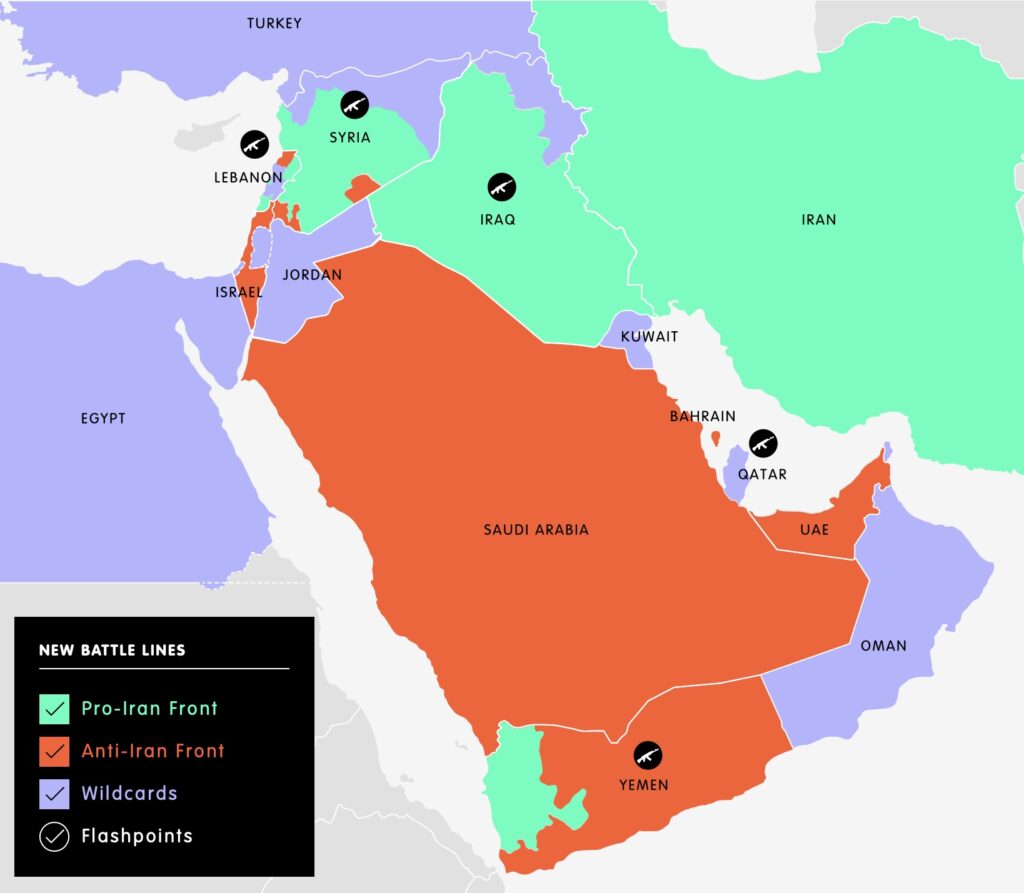
The map illustrates the regional geopolitical alignment around Iran in the Middle East, showing how the region is broadly divided into competing blocs. Countries such as Syria, Iraq, and groups in Lebanon and Yemen are often aligned with Iran through political or military cooperation, forming what is sometimes called the “Axis of Resistance.” This network includes state partners and non-state actors such as Hezbollah and other militias that support Iran’s regional influence. In contrast, a counter-bloc led by Saudi Arabia, the UAE, and often supported by Israel and Western allies seeks to limit Iran’s power and expansion in the region. Between these camps are “wildcard” states like Turkey, Qatar, and Oman, which maintain more flexible or pragmatic relationships with both sides. Together, these rival alliances create a complex strategic landscape where competition for influence frequently plays out through diplomacy, proxy conflicts, and shifting regional partnerships.
source: ECFR
16. How Strong Is Iran’s Military?
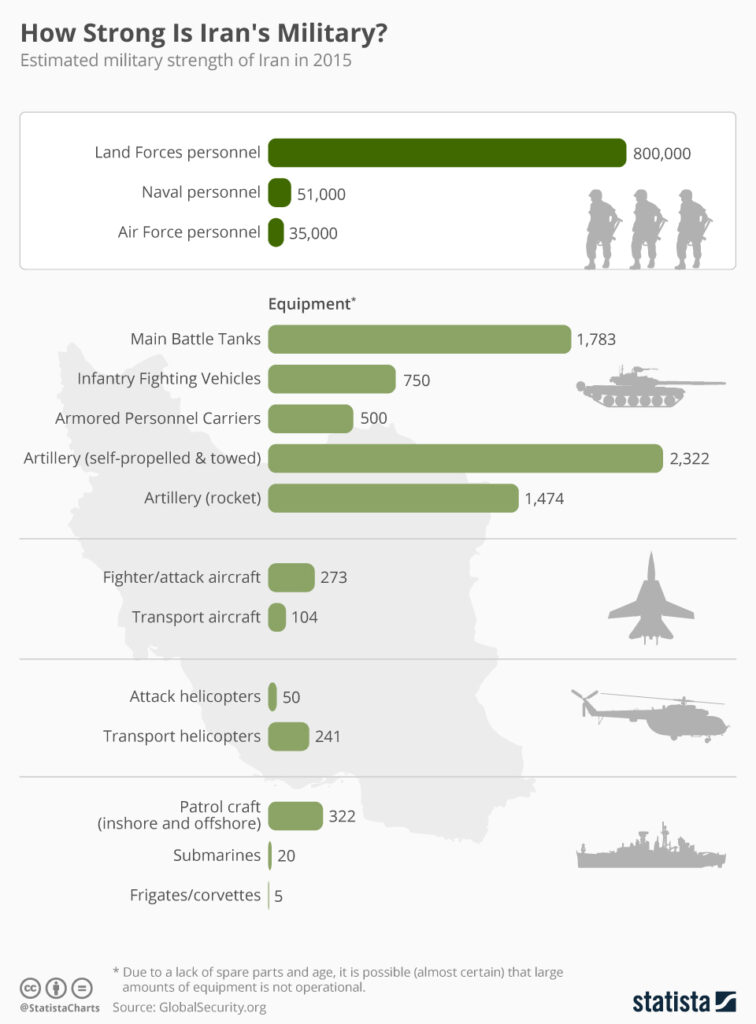
Iran possesses one of the largest military forces in the Middle East, with an estimated nearly 900,000 active personnel, according to data compiled by GlobalSecurity and visualized by Statista. The armed forces are divided between the regular army (Artesh) and the Islamic Revolutionary Guard Corps (IRGC), which plays a major role in national defense and regional operations. While much of Iran’s conventional equipment—such as aircraft and armored vehicles—dates back to the era before the 1979 revolution and includes aging U.S.-made systems like F-14 and F-4 fighter jets, the country compensates through a strategy focused on missiles, drones, naval forces in the Persian Gulf, and asymmetric warfare capabilities. Despite technological limitations and sanctions that restrict access to spare parts and modern weapons, the large manpower base and focus on deterrence make Iran a significant regional military power.
source: Statista
17. Missiles of Iran
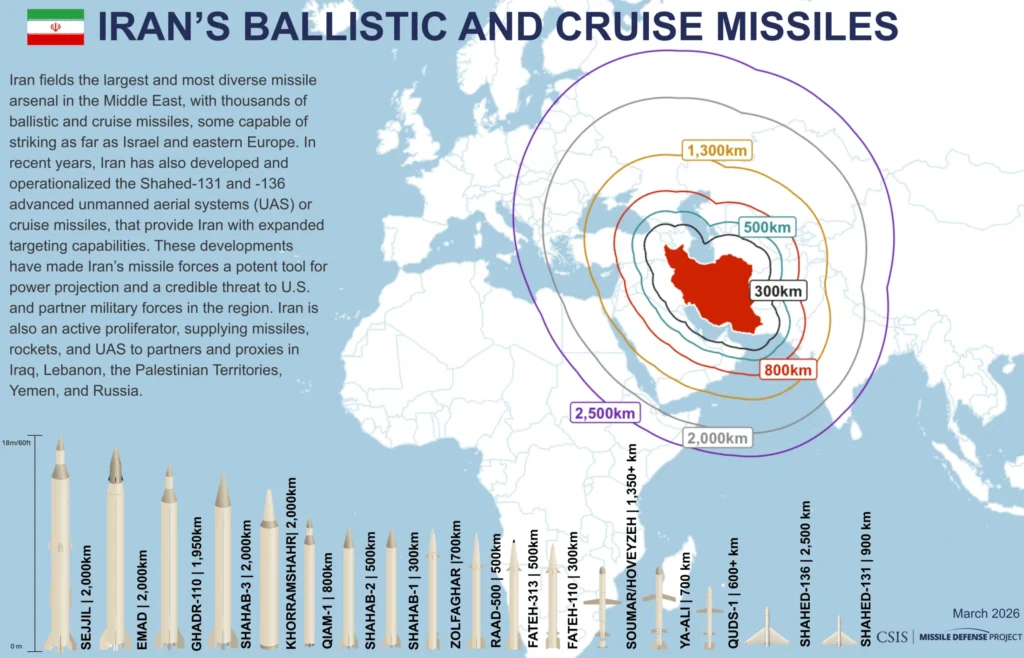
Iran possesses the largest and most diverse ballistic missile arsenal in the Middle East, which has become a central pillar of its military strategy and deterrence. According to the CSIS Missile Threat project, Iran fields a wide range of missiles—from short-range systems like the Fateh-110 and Fateh-313 (200–500 km range) to medium-range missiles such as the Shahab-3 and Khorramshahr, capable of reaching 1,300–2,000 km or more. These longer-range systems allow Iran to threaten targets across the Middle East, including Israel and U.S. military bases in the region. Many of Iran’s missiles are road-mobile and solid-fuel, which increases survivability and allows them to be launched quickly. While the accuracy of some systems remains limited compared with Western missiles, Iran has steadily improved guidance systems and payload capabilities over the past two decades, making its missile force one of the country’s most important tools for regional influence and deterrence.
source: Missiles Treat
18. Where Israel attacked Iran in June 2025
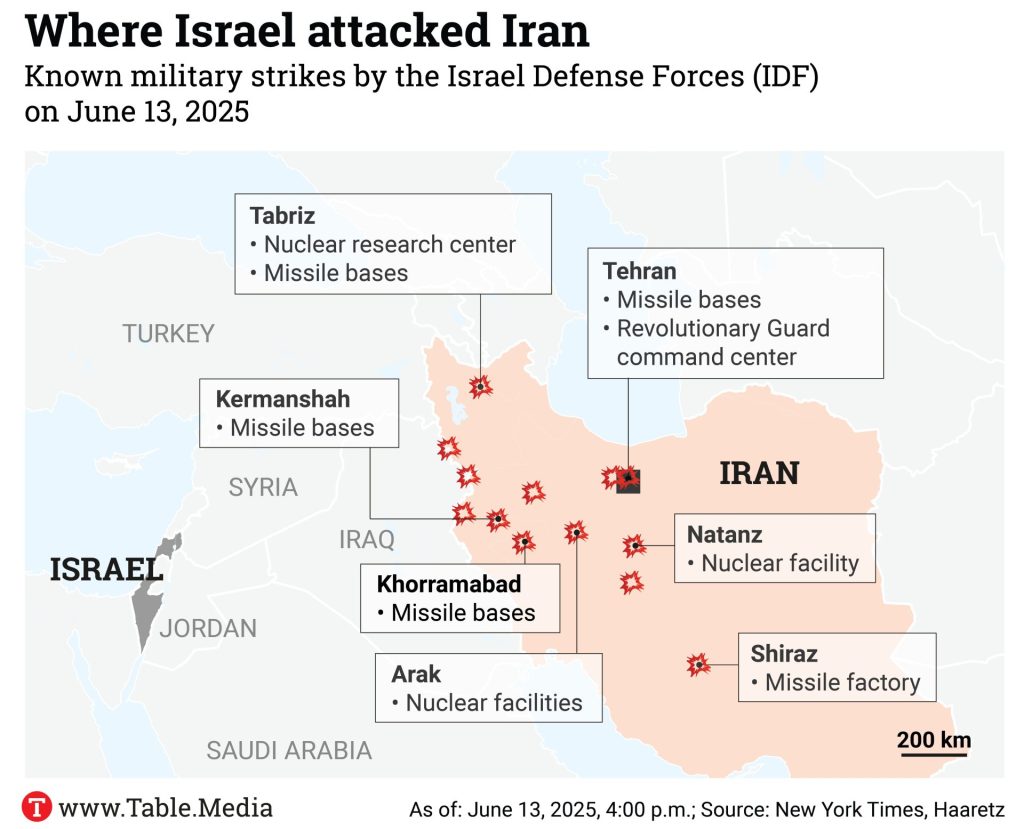
The map shows the main locations targeted during Israeli strikes on Iran on June 13, 2025, focusing primarily on nuclear facilities, missile bases, and military command centers. Key sites include the Natanz nuclear enrichment facility, one of the core elements of Iran’s nuclear program, as well as installations in Arak associated with nuclear infrastructure. Several strikes also targeted missile bases and factories in cities such as Kermanshah, Khorramabad, Shiraz, and Tabriz, reflecting efforts to weaken Iran’s missile capabilities. In Tehran, attacks reportedly focused on Revolutionary Guard command structures and missile-related infrastructure. The distribution of the targets across western and central Iran highlights the strategic aim of disrupting both Iran’s nuclear program and its missile production and deployment network.
source: Table Media
19. Map of Iran War attacks, March 8th, 2026
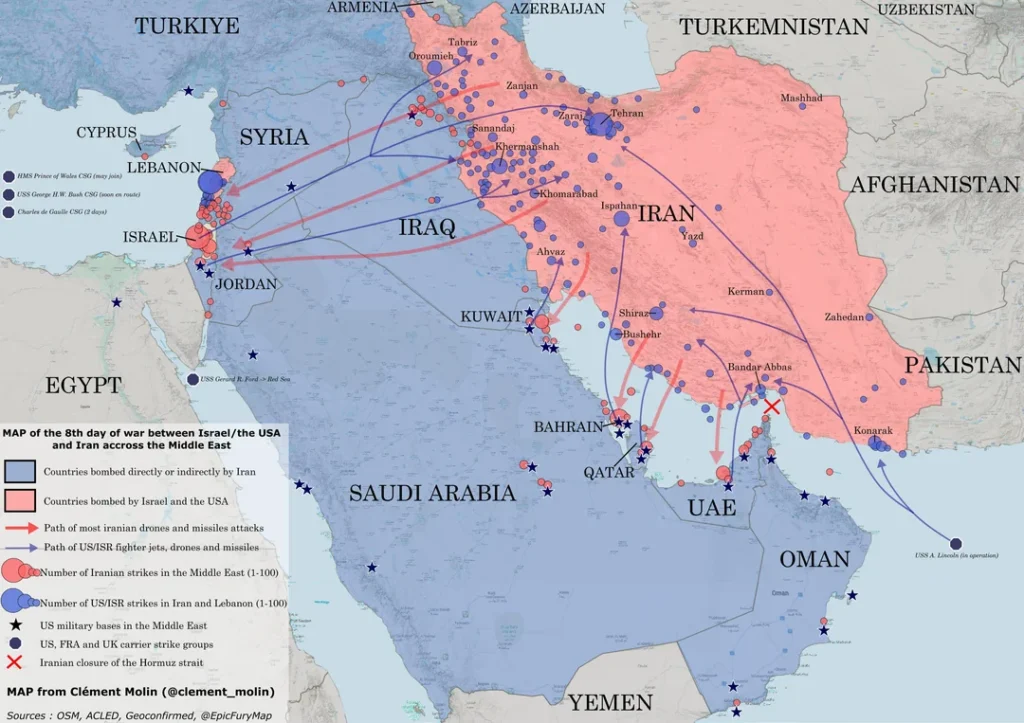
The map illustrates how the current conflict has expanded beyond Iran’s borders into a region-wide confrontation involving Israel, the United States, and multiple Middle Eastern countries. According to available data, U.S. and Israeli forces conducted roughly 4,500 strikes across Iran, targeting air defenses, missile launchers, military bases, and command centers. In response, Iran launched about 3,500 attack vectors—including around 905 missiles as well as large numbers of drones—against Israel and U.S. positions in the region. These strikes have reached targets across the Middle East, including Israel, Iraq, Kuwait, the UAE, Bahrain, and other Gulf states hosting U.S. military bases. The map also highlights the strategic geography of the conflict: Iran’s missile and drone launches project power across the region, while U.S. naval forces, air bases, and carrier strike groups form a network supporting the counter-offensive. The pattern of attacks shows how quickly the war has transformed from a bilateral confrontation into a multi-country regional conflict centered on Iran’s missile capabilities and the U.S. military presence in the Middle East.
source: X
20. Geography of Iran explained

